
ˆ z n sx n x · x La varianza del estimador 1 E ... ley chi-cuadrado con n-2 grados de libertad,...
13
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 1/51 Tema 2. Problemas de inferencia estadística en el modelo de regresión lineal simple. 1. Inferencia respecto a los parámetros 1.1 Intervalos de confianza respecto al parámetro 1 1.2 Intervalos de confianza respecto al parámetro 0 1.3 Intervalos de confianza respecto al parámetro 2 2. El contraste de regresión 2.1 El contraste de la pendiente (t-Student) 2.2 El contraste de regresión con relación al análisis de la varianza (F-Fisher) 3. El contraste de las hipótesis mediante residuos 3.1 Introducción 3.2 El análisis de los residuos 3.3 Observaciones con influencia en regresión simple 4. Transformaciones 5. Predicción 5.1 Estimación de las medias condicionadas 5.2 Predicción de una nueva observación 5.3 Bandas de confianza Métodos de Regresión - Grado en Estadística y Empresa Tema 2 2/51 1. Inferencia respecto a los parámetros La construcción de los intervalos de confianza para los parámetros 1 , 0 y 2 se realizará a partir de las distribuciones de probabilidad de 2 0 1 ˆ , ˆ R s y . 1.1 Intervalo de confianza para 1 Caso 1 : Si 2 es conocida, vimos en el apartado 4.1 del Tema 1, que ) 1 , 0 ( ~ ˆ , ~ ˆ 1 1 2 2 1 1 N s n ns N x x Proposición: El intervalo x x s n z s n z C I 2 / 1 1 2 / 1 1 1 ˆ , ˆ ) .( . , donde 2 / 1 z es el percentil (1- /2)100 de la ley normal estándar, es un intervalo de confianza para 1 con un nivel de confianza 1- cuando 2 es conocida. (Demostración) Métodos de Regresión - Grado en Estadística y Empresa Tema 2 3/51 De la fórmula anterior se deduce que la amplitud del intervalo depende de: El nivel de confianza: A mayor nivel de confianza, mayor es la amplitud y, por tanto, menos precisión. La varianza del estimador 1 ˆ : A mayor varianza, mayor amplitud. Caso 2 : Cuando 2 es desconocida, ésta se sustituye por su estimador, 2 R s , y entonces 2 1 1 ~ ˆ n x R t s n s Proposición: El intervalo x R x R s n s t s n s t C I 2 / 1 1 2 / 1 1 1 ˆ , ˆ ) .( . , donde 2 / 1 t es el percentil (1- /2)100 de la ley t de Student con n-2 grados de libertad, es un intervalo de confianza para 1 con un nivel de confianza 1- cuando 2 es desconocida. (Demostración análoga) Métodos de Regresión - Grado en Estadística y Empresa Tema 2 4/51 1.2 Intervalo de confianza para 0 Análogamente se deducen los intervalos de confianza para el parámetro 0 : Caso 1 : Si 2 es conocida, entonces: ) 1 , 0 ( ~ 1 ˆ 1 , ~ ˆ 2 2 0 0 2 2 2 0 0 N s x n s x n N x x Proposición: El intervalo 2 2 2 / 1 0 2 2 2 / 1 0 0 1 ˆ , 1 ˆ ) .( . x x s x n z s x n z C I , donde 2 / 1 z es el percentil (1- /2)100 de la ley normal estándar, es un intervalo de confianza para 0 con un nivel de confianza 1- cuando 2 es conocida.
Transcript of ˆ z n sx n x · x La varianza del estimador 1 E ... ley chi-cuadrado con n-2 grados de libertad,...

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 1/51
Tema 2. Problemas de inferencia estadística en el modelo de regresión lineal simple.
1. Inferencia respecto a los parámetros 1.1 Intervalos de confianza respecto al parámetro 11.2 Intervalos de confianza respecto al parámetro 01.3 Intervalos de confianza respecto al parámetro 2
2. El contraste de regresión 2.1 El contraste de la pendiente (t-Student)2.2 El contraste de regresión con relación al análisis de la varianza (F-Fisher)
3. El contraste de las hipótesis mediante residuos 3.1 Introducción 3.2 El análisis de los residuos 3.3 Observaciones con influencia en regresión simple
4. Transformaciones 5. Predicción
5.1 Estimación de las medias condicionadas 5.2 Predicción de una nueva observación 5.3 Bandas de confianza
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 2/51
1. Inferencia respecto a los parámetros
La construcción de los intervalos de confianza para los parámetros 1, 0 y 2 se
realizará a partir de las distribuciones de probabilidad de 2
01ˆ,ˆ
Rs y .
1.1 Intervalo de confianza para 1Caso 1: Si 2 es conocida, vimos en el apartado 4.1 del Tema 1, que
)1,0(~ˆ
,~ˆ 112
2
11 N
snns
N
x
x
Proposición: El intervalo
xx snz
snzCI 2/112/111
ˆ,ˆ).(.,
donde 2/1z es el percentil (1- /2)100 de la ley normal estándar, es un intervalo de confianza para 1 con un nivel de confianza 1- cuando 2 es conocida.(Demostración)
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 3/51
De la fórmula anterior se deduce que la amplitud del intervalo depende de:
El nivel de confianza: A mayor nivel de confianza, mayor es la amplitud y, por tanto, menos precisión.
La varianza del estimador 1̂ : A mayor varianza, mayor amplitud.
Caso 2: Cuando 2 es desconocida, ésta se sustituye por su estimador,2Rs , y entonces
211 ~
ˆn
x
Rt
sns
Proposición: El intervalo
x
R
x
R
snst
snstCI 2/112/111
ˆ,ˆ).(.,
donde 2/1t es el percentil (1- /2)100 de la ley t de Student con n-2 grados de libertad, es un intervalo de confianza para 1 con un nivel de confianza 1- cuando 2
es desconocida. (Demostración análoga)
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 4/51
1.2 Intervalo de confianza para 0Análogamente se deducen los intervalos de confianza para el parámetro 0:
Caso 1: Si 2 es conocida, entonces:
)1,0(~1
ˆ1,~ˆ
2
200
2
22
00 N
sx
n
sx
nN
x
x
Proposición: El intervalo
2
2
2/102
2
2/100 1ˆ,1ˆ).(.xx s
xn
zsx
nzCI
,
donde 2/1z es el percentil (1- /2)100 de la ley normal estándar, es un intervalo de confianza para 0 con un nivel de confianza 1- cuando 2 es conocida.

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 5/51
Caso 2: Si 2 es desconocida, entonces:
2
2
200 ~
1
ˆn
x
R
t
sx
ns
Proposición: El intervalo
2
2
2/102
2
2/100 1ˆ,1ˆ).(.x
R
x
R
sx
nst
sx
nstCI
,
donde 2/1t es el percentil (1- /2)100 de la ley t de Student con n-2 grados de libertad, es un intervalo de confianza para 0 con un nivel de confianza 1- cuando 2
es desconocida.
Observación: Para n 30, aunque 2 sea desconocida, la ley t de Student suele aproximarse por una ley normal estándar. Es decir, que si n 30 entonces
.2/12/1 zt
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 6/51
Ejemplo: Hallar los I.C. al 99% para los parámetros 1, 0 del Ejemplo 1 (densidad del tráfico) del Tema 1.
En el Ejemplo 1 (del Tema 1) se intentaba modelar la velocidad de circulación (y) en cierta carretera en función de la densidad del tráfico (x).
Para este conjunto de datos se tenía que: .09.8ˆ,057.0ˆ,44.54,0377.0,73.635,24 01
22 xssn Rx
Además, 2 es desconocida. Los I.C. deben calcularse al (1- )100%=99%, por tanto, 82.2995.02/1 tt .
3559.8,8240.773.635
44.541240377.082.209.81ˆ).(.
0526.0,0614.073.63524
0377.082.2057.0ˆ).(.
2
2
2
2/100
2/111
x
R
x
R
sx
nstCI
snstCI
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 7/51
Ejercicio: Hallar los I.C. al 99% para los parámetros 1, 0 del Ejemplo 2 (esperanza de vida) del Tema 1.
Ejercicio 7. a) Hallar un intervalo de confianza para la pendiente de la recta y=5.9+0.59 x, donde
y es el salario mensual y x son los años de escolarización, para un nivel de confianza del 90%.
b) Lo mismo para el término independiente.
Ejercicio 8. Hallar los intervalos de confianza al 95% para 0, 1 para y=79.3210-1.3765 x, donde y es la longitud de la línea de la mano y x es la edad al morir.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 8/51
1.3 Intervalo de confianza para 2
Utilizando el resultado que vimos en el apartado 5 del Tema 1:
222
2
~)2(n
Rsn
se puede deducir el intervalo de confianza para la varianza del modelo.
Proposición: El intervalo
2
2/
2
2/1
2 2,2).(. RR sxns
xnCI ,
donde 2/12/ , xx son, respectivamente, los percentiles ( /2)100 y (1- /2)100 de la ley chi-cuadrado con n-2 grados de libertad, es un intervalo de confianza para 2 con un nivel de confianza 1- .

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 9/51
Ejemplo: Hallar el I.C. al 90% para el parámetro 2 del Ejemplo 1 (densidad del tráfico) del Tema 1. Para este conjunto de datos se tenía que .0377.0,24 2
Rsn El I.C. debe calcularse al (1- )100%=90%, por tanto, .9.33,9.33 95.02/105.02/ xxxx .
0691.0,0245.00377.03.12
22,0377.09.33
222,2).(. 2
2/
2
2/1
2RR s
xns
xnCI
Ejercicio 9. Hallar un intervalo de confianza al 90% para 2 con los datos del Ejercicio 5 (longitud de la línea de la mano).
Ejercicio 10. Hallar un intervalo de confianza al 95% para 2 con los datos del Ejercicio 6 (salario-escolarización).
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 10/51
2. El contraste de regresión
2.1. El contraste de la pendiente (t- Student)
El objetivo general de los contrastes de hipótesis es ayudar al investigador a tomar una decisión sobre la población de estudio, a partir de una muestra de ella.
En este caso, el contraste de hipótesis sobre la pendiente nos ayudará a decidir si el parámetro 1 admite un valor concreto 1
*.
Mediante un contraste de hipótesis podremos responder a preguntas como, por ejemplo: 1) ¿El valor 1
* es un valor admisible para 1?2) ¿Es realmente significativa (es decir, influye) la variable x sobre la variable y?3) Se sabe de investigaciones anteriores que 1 vale 1
*, ¿mi resultado es similar, teniendo en cuenta que a partir de una muestra mi estimación es 1̂ ?
El planteamiento es similar en cualquiera de los tres casos.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 11/51
2.1.1. Contraste bilateral: Se plantean dos hipótesis: la hipótesis nula, H0, y la hipótesis alternativa, H1:
*11
*10
1
1
:
:
H
H
Para resolver el contraste se construye un estadístico de contraste, cuya distribución debe ser conocida bajo el supuesto de la hipótesis H0. En este caso, se utiliza:
2
*11
exp ~ˆ
n
x
Rt
snst
Cuanto más parecidos sean la estimación 1̂ y el valor del parámetro que se quiere contrastar 1
*, más próximo a cero será el valor de texp.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 12/51
Utilizando la ley del estadístico de contraste, se construyen las zonas de rechazo y deaceptación de H0, para un nivel de significación fijado:
Regla de decisión:
Para un nivel de significación fijado, se rechaza la hipótesis H0 si
)2(2/1exp
ntt

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 13/51
2.1.2. Contraste unilateral izquierdo:
Hipótesis del contraste:
*111
*110
:
:
HH
x
R
snst
*11
exp
ˆ
Regla de decisión:
Para un nivel de significación fijado, , se rechaza la hipótesis H0 si
)2(1exp
ntt
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 14/51
2.1.3. Contraste unilateral derecho:
Hipótesis del contraste:
*111
*110
:
:
HH
x
R
snst
*11
exp
ˆ
Regla de decisión:
Para un nivel de significación fijado, , se rechaza la hipótesis H0 si
)2(1exp
ntt
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 15/51
Observaciones: Es de particular interés el contraste de significación del parámetro 1, que consiste en tomar 1
*=0 en cualquiera de los contrastes anteriores:
0:0:
11
10
HH
0:0:
11
10
HH
0:0:
11
10
HH
bilateral unilateral izquierdo unilateral derecho En este caso, el no rechazar la hipótesis H0 y, por tanto, concluir que el valor 0 es un valor admisible para el parámetro 1, es equivalente a afirmar que la variable explicativa no influye en la variable respuesta.
Los paquetes estadísticos, como Statgraphics, basan el criterio de decisión en el p-valor, que para los contrastes unilaterales es la probabilidad de cola asociada al valor del estadístico de test. Para un nivel de significación fijado , se rechaza la hipótesis H0 si p-valor < .
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 16/51
Ejemplo: Contrastar con los datos del Ejemplo 1 (densidad del tráfico) la hipótesis nula de que la densidad no influye (linealmente) en la velocidad frente a la alternativa de que un incremento de la densidad produce un descenso en la velocidad, para un nivel de significación del 5%.x=”densidad del tráfico”, y=”velocidad”,
.09.8ˆ,057.0ˆ,0377.0,73.635,24 0122Rx ssn
Recta de regresión: y=8.09-0.057xPlanteamos el siguiente contraste:
0:0:
11
10
HH
A partir de la información muestral, calculamos el estadístico de test:
26.36
)73.635(240377.0
0057.0ˆ *11
exp
x
R
snst

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 17/51
Comparamos el valor del estadístico de test con el percentil 5% de la ley t de Student con 22 grados de libertad:
)22(95.0exp 72.126.36 tt
¿Cuánto vale el p-valor?
21032492)26.36( 22 E-.tP
Concluimos que 1<0 y, por tanto, la velocidad está influida por la densidad del tráfico, para un nivel de significación del 5%.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 18/51
Contraste de hipótesis a través del intervalo de confianza
El intervalo de confianza permite realizar el contraste de hipótesis bilateral.
Por ejemplo, para resolver el contraste de significación de 1, para un nivel de significación fijado , podemos utilizar el intervalo de confianza de 1 de la forma siguiente:
Basta verificar si para un nivel de confianza del (1- )100%, el valor 0 está contenido en el I.C. siguiente:
x
Rn
x
Rn
snst
snstCI )2(
2/11)2(2/1111
ˆ,ˆ).(.
Si el valor 0 pertenece a este intervalo concluiremos que 0 es un valor admisible para 1
para el nivel de significación .
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 19/51
Ejercicio 11. (producción-fertilizantes) Se dispone de los siguientes datos experimentales obtenidos en un campo de cultivo que relacionan la producción con la cantidad de fertilizante aplicado.
Fertilizantes (kg/hect.) x 100 200 300 400 500 600 700
Producción (kg/hect.) y 40 45 50 65 70 70 80
Hallar: a) La nube de puntos y dibujar una recta que pase “lo más cerca posible” de todos sus
puntos y en especial por el centroide. b) La recta de regresión de y sobre x. Interpretar los coeficientes. c) La varianza residual. d) I.C. al 95% para 1.e) I.C. al 95% para 2 y para .f) Coeficiente de correlación y coeficiente de determinación. Interpretar los resultados. g) Si se aplican 350kg/hect. de fertilizante, ¿qué producción se obtendrá? ¿Y con 1000
kg/hect.?h) Realiza un contraste de hipótesis con un nivel de significación del 5% para comprobar
si la producción depende del fertilizante.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 20/51
2.2. Contraste de regresión (ANOVA)
Definición: Se denomina contraste de regresión al contraste de hipótesis sobre la pendiente de la recta de regresión.
xxyEHxyEH
HH
101
00
11
10
)/(:)/(:
0:0: constante
Aunque en la sección anterior ya hemos deducido este contraste, aquí vamos a resolverlo mostrando su relación con el análisis de la varianza (ANOVA).
Recordemos la descomposición de la variabilidad:
)ˆ()2()ˆ(
ˆ)ˆ(
)(
221
22
1
2
1
2
221
1
2
2
1
2
xyR
n
ii
n
iii
x
n
ii
y
n
ii
ssnsneyyVNE
snyyVE
nsyyVT

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 21/51
Por un lado, sabemos que: 2
22 ~ nVNE
Y por otro, se puede demostrar (Peña vol. II, apéndice 11B) que cuando 1=0 (es decir, bajo el supuesto de H0 ):
212
212 ~~ VEVT
n y
Por tanto, si 1=0, se construye el siguiente estadístico de contraste:
lib.gr.2-n y 1conFisherdeF2,12
221
2exp ~ˆ
2
1n
R
x
R
Fs
snsVE
nVNE
VE
F
La regla de decisión ahora es: Para un nivel de significación fijado, , se rechaza la
hipótesis H0 si 2,1exp nFF
Cuando Fexp es grande significa la variabilidad explicada por el modelo es mucho mayor que la variabilidad residual.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 22/51
Este contraste suele realizarse a partir de la tabla ANOVA:
Fuente devariación
Sumas de Cuadrados
Gradosde libertad
Cociente o varianza
Fexp
VE 221̂ xsn 1 22
1̂ xsn2
221̂
R
x
ssn
VNE2)2( Rsn n-2 2
Rs
VT 2yns n-1
El estadístico Fexp compara el cuadrado del estimador 1̂ con su varianza.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 23/51
Atención!: Este contraste supone linealidad, puesto que compara dos modelos:
0)(0)(constante
1
1
xxyEHxyEH
101
00
)/(:)/(:
es decir, analiza si una recta con pendiente no nula representa mejor a los datos que una recta horizontal. Por tanto, aceptar H0 (recta horizontal) no implica que x e y sean independientes.
-1 -0.5 0 0.5 1
En este caso, se aceptaría H0 porque la recta horizontal tiene mejor ajuste que cualquier otra recta.
Aunque 1=0, existe relación entre x e y.
Para evitar casos patológicos como este, es siempre conveniente representar los datosmediante un diagrama de dispersión.
Solamente podremos concluir a partir del contraste de regresión que las variables x e yson independientes si conjuntamente tienen ley normal bivariante.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 24/51
Equivalencia entre el contraste de regresión y el contraste de significación de 1
Contraste de regresión:
2,12
221
exp ~ˆ
nR
x Fs
snF
Contraste de significación de 1:
211
exp ~ˆˆ
nR
x
xR
tssn
snst
Elevando texp al cuadrado se tiene que:
exp
2
12exp
ˆF
ssntR
x

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 25/51
Ejemplo: Con los datos del Ejercicio 11 (producción-fertilizantes) realizar un contraste de regresión con un nivel de significación del 1%.
y=”producción” (en kg/hect), x=”fertilizantes” (en kg/hect). Para este conjunto de datos se tenía que:
.8.32ˆ,068.0ˆ,0559.11,40000,7 0122Rx ssn
Recta de regresión estimada: y=32.8+0.068xEl contraste de regresión que se plantea es:
0:0:
)/(:)/(:
11
10
101
00
HH
xxyEHxyEH
Calculamos el estadístico de contraste:
1067.1170559.11
40000068.07ˆ 2
2
221
expR
x
ssnF
Puesto que Fexp =117.1067>16.23= F1, 5 (0.05), se rechaza H0, con lo que se concluye que la recta con pendiente no nula es mejor para representar estos datos.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 26/51
Otra forma de resolver este Ejemplo es mediante la tabla ADEVA (ANOVA):
Fuente devariación
Sumas de Cuadrados
Gradosde libertad
Cociente o varianza
Fexp
VE 1294.72 1 1294.72 117.1067VNE 55.2795 5 11.0559 VT 1349.9997 6
Fexp =117.1067>16.23= F1,5(0.05), se rechaza H0, sí existe relación lineal entre x e y.
Ejercicio 12. Dada la ecuación de regresión y=3+4x indicar, mediante el contraste de regresión, si hay evidencias de que y depende linealmente de x con un nivel de significación =0.01 y sabiendo que R2=0.4 y n=25.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 27/51
3. Contraste de las hipótesis mediante los residuos: Diagnosis del modelo.
Se realiza mediante el estudio gráfico de los residuos. Objetivo: validar las hipótesis sobre las que se basa el modelo de regresión.
Linealidad
xxyEiuE 10)|(0)( ó
Normalidad
Normalui ~
Homocedasticidad 2)var( iu
Independencia
jiuu ji ,0),cov(
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 28/51
Permite depurar los datos: Eliminar atípicos (cuando sea conveniente) Mejorar la Normalidad Mejorar la homocedasticidad Transformar un modelo no lineal en uno que sea lineal.
Gráficos preliminares: Conjuntos: diagrama de dispersión (detectar desviaciones de la linealidad) Individuales: hitogramas, gráficos de cajas (detectar desviaciones de la normalidad: más de una moda, asimetría, atípicos…)
Gráficos posteriores: Residuos vs. Valores predichos ( ) Residuos vs. Variable explicativa (x) Residuos vs. Sencuencia temporal Residuos vs. Otra variable de interés

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 29/51
Falta de linealidad
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 30/51
Falta de homocedasticidad
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 31/51
Falta de independencia entre los residuos
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 32/51

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 33/51
Observación influyente
Es una observación atípica (xA,yA) cuya exclusión produce un cambio drástico en la recta de regresión.
Posibles causas de una observación influyente
1) error de observación
2) modelo incorrecto: no linealidad: la relación entre x e y no es lineal cerca de xA
heterocedasticidad: la varianza aumenta mucho con x. variable desconocida que ha tomado un valor distinto en xA
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 34/51
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 35/51 Métodos de Regresión - Grado en Estadística y Empresa Tema 2 36/51
Resumen de posibles problemas a tener en cuenta
i. La función de regresión no es lineal.
Diagrama de dispersión:Observar si los datos se desvían de manera sistemática de la recta estimada, en particular si lo hacen sobre una trayectoria curvilínea.
Residuos vs. valores predichos o vs. variable independiente.
Posible remedio (a nuestro alcance):Por lo general, basta transformar solamente x.

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 37/51
ii. Los errores no siguen una ley Normal.
Gráficos descriptivos de los residuos: Histograma, gráfico de caja,…
Gráficos de Probabilidad Normal (Normal Probability Plot). Desviaciones respecto a las colas del gráfico indican posible sesgo o colas muy pesadas.
Normal Probability Plot for lifeexpf
53 58 63 68 73 78 83
lifeexpf
0,115
2050809599
99,9
perc
enta
ge
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 38/51
Gráfico de residuos estandarizados vs. valores predichos: Si los errores son normales, los residuos estandarizados deberían encontrarse en su mayoría en la franja horizontal (-3, 3).
Residual Plot
predicted lifeexpf
Stud
entiz
ed re
sidu
al
55 60 65 70 75 80 85-2,6
-1,6
-0,6
0,4
1,4
2,4
3,4
Posible remedio (a nuestro alcance): Por lo general, basta transformar solamente la variable y, puesto que es la distribución de la variable respuesta la que, por hipótesis, debe ser Normal.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 39/51
iii. Los errores no tienen varianza constante.
Residuos vs. valores predichos o vs. variable independiente. Buscar formas de trompeta en la nube de residuos.
Residuos al cuadrado o en valor absoluto vs. valores predichos o vs. variable independiente:Puede ser más útil realizar este gráfico que el anterior, puesto que el signo de los residuos no tiene importancia y, en cambio, será más fácil de apreciar los cambios en la varianza.
Posible remedio (a nuestro alcance): Por lo general, basta transformar solamente la variable y, puesto que es la varianza de la variable respuesta la que, por hipótesis, debe ser constante.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 40/51
iv. Los errores no son independientes.
Residuos vs. secuencia temporal
Cuando los errores son independientes, los residuos deberían fluctuar en un patrón aleatorio alrededor del 0. Si se observa algún patrón definido, ello puede ser debido a que los errores están correlacionados.
v. Se han omitido variables en el modelo
Residuos vs. variables omitidas en el modelo.
Dividir la muestra en grupos según los valores de alguna variable categórica, o variable categorizada, (sexo, edad, …) y examinar los residuos de cada grupo por separado.
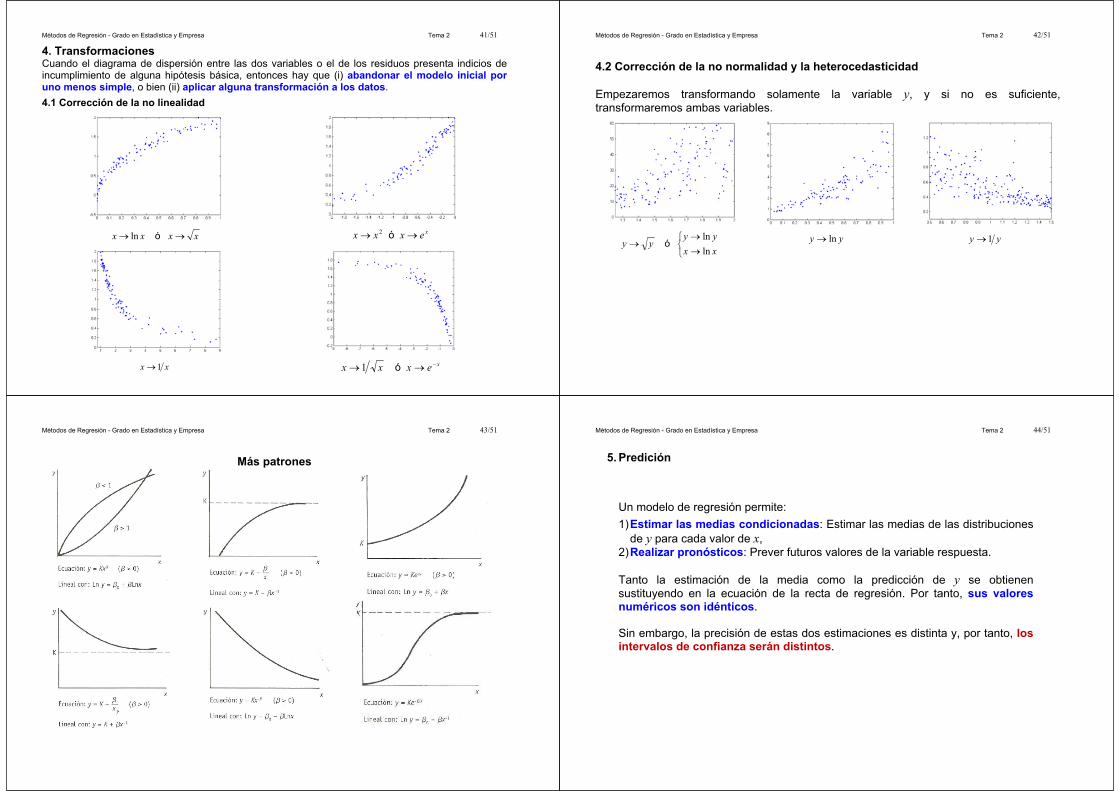
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 41/51
4. Transformaciones Cuando el diagrama de dispersión entre las dos variables o el de los residuos presenta indicios de incumplimiento de alguna hipótesis básica, entonces hay que (i) abandonar el modelo inicial poruno menos simple, o bien (ii) aplicar alguna transformación a los datos.4.1 Corrección de la no linealidad
xxxx óln xexxx ó2
xx 1 xexxx ó1
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 42/51
4.2 Corrección de la no normalidad y la heterocedasticidad
Empezaremos transformando solamente la variable y, y si no es suficiente, transformaremos ambas variables.
xxyy
yylnln
ó yy ln yy 1
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 43/51
Más patrones
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 44/51
5. Predición
Un modelo de regresión permite: 1)Estimar las medias condicionadas: Estimar las medias de las distribuciones
de y para cada valor de x,2)Realizar pronósticos: Prever futuros valores de la variable respuesta.
Tanto la estimación de la media como la predicción de y se obtienen sustituyendo en la ecuación de la recta de regresión. Por tanto, sus valores numéricos son idénticos.
Sin embargo, la precisión de estas dos estimaciones es distinta y, por tanto, losintervalos de confianza serán distintos.

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 45/51
5.1. Estimación de las medias condicionadas (o variación esperada)
Modelo: yi= 0+ 1 xi + ui, donde ui, i=1,…,n, son v.a. i.i.d.~N(0, 2).
Vimos en el Tema 1 que: E(y/x)= 0+ 1 x,
El nuevo parámetro que se quiere estimar es la media de y condicionada a que xtome un valor concreto xh, es decir:
E(y/x=xh)= 0+ 1 xh=mh
El estimador puntual de mh es:
hh xy 10ˆˆˆ ,
que tiene ley normal, al ser combinación lineal de normales.
Proposición: hh xy 10ˆˆˆ es un estimador insesgado de mh, cuya varianza es
2
2
1
ˆdonde,ˆ
)ˆvar(
x
hh
hh
sxx
nnn
y
(Demostración)
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 46/51
Observaciones:
hn̂ se denomina número equivalente de observaciones para la estimación de mh,2
x
hs
xxes el cuadrado de la distancia de Mahalanobis entre el punto xh y la
media de x,hn̂ depende de la distancia de Mahalanobis entre el punto xh y la media de x, y
determina la precisión de la estimación, es decir: Cuánto más cerca está xh de la media de x (menor distancia de Mahalanobis)
mayor hn̂ menor )ˆvar( hy y, por tanto, mayor precisión.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 47/51
Intervalo de confianza para mh
Utilizaremos la ley de probabilidad de su estimador puntual hh xy 10ˆˆˆ .
Caso 1: 2 conocida,
)1,0(~ˆ
ˆˆ
,~ˆ2
Nnmy
nmNy
h
hh
hhh
Caso 2: 2 desconocida,
2~ˆ
ˆn
hR
hh tnsmy
En general, se estará en la hipótesis del Caso 2, con lo que el I.C. para mh al (1- )100%será:
hRhh n
stymCIˆ1ˆ).(.
21
donde t1- /2 es el percentil (1- /2)100% de la ley t de Student con n-2 grados de libertad y
2
1
ˆ
x
h
h
sxx
nn
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 48/51
5.2 Predicción de una nueva observación (pronóstico) Se quiere prever el valor futuro de la variable respuesta cuando x=xh. Por tanto, se tiene una nueva v.a.
yh= 0+ 1 xh + uh, donde uh~N(0, 2) y es independiente de u1, u2,…, un.La predicción o pronóstico de la variable respuesta se obtiene sustituyendo en la ecuación de la recta de regresión:
hh xy 10ˆˆˆ
pero, ¿y si se quiere un intervalo de predicción?Aclaración: El intervalo que se construye para los valores futuros de la variable respuesta, en realidad, no es un intervalo de confianza porque no se está estimando ningún parámetro. Se trata de un intervalo de valores probables para la variable aleatoria yh, que se denomina intervalo de predicción o de pronóstico.Este intervalo al (1- )100% es
hRhh n
styyˆ11ˆ
21
donde t1- /2 es el percentil (1- /2)100% de la distribución t de Student con n-2 gr. lib. y
2
1
ˆ
x
h
h
sxx
nn

Métodos de Regresión - Grado en Estadística y Empresa Tema 2 49/51
¿Cómo se deduce este intervalo?
Se considera la variable diferencia, es decir, el residuo hhh yye ˆ , que tiene ley normal al ser combinación lineal de normales.
Se obtienen su esperanza y varianza:
hhhhhh
mhh
mhhhhhh
nnyyyy
yEuExyuxEyyEhh
ˆ11
ˆ)ˆvar()var()ˆvar(
0)ˆ()()ˆ()ˆ(
22
2
01010
Observación: La varianza se obtiene como suma de varianzas puesto que hh yy ˆ, son independientes al serlo uh de u1, u2,…, un.
Por tanto, se tiene que:
)1,0(~
ˆ11
ˆˆ11,0~ˆ 2 N
n
yyn
Nyy
h
hh
hhh
siempre que 2 sea conocida.
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 50/51
Si 2 es desconocida, entonces se sustituye por su estimador, y entonces:
2~
ˆ11
ˆn
hR
hh t
ns
yy
Puesto que esta será la situación habitual, el intervalo de predicción para la respuesta concreta yh es:
hRhh n
styyˆ11ˆ
21
Observaciones: El intervalo de predicción es mucho más ancho que el I.C:(mh), porque se añade la variabilidad de una observación alrededor de la media.
En ambos intervalos, la amplitud aumenta cuando aumenta la distancia de Mahalanobis entre xh y la media de x.
Ambas amplitudes son mínimas cuando xxh .
Métodos de Regresión - Grado en Estadística y Empresa Tema 2 51/51
5.3 Bandas de confianza Las bandas de confianza para la predicción de las medias condicionadas (respuesta media) se obtienen uniendo los extremos de los intervalos construidos para el mismo nivel de confianza 1- , y para cada valor de x.Análogamente, también pueden construirse Las bandas de confianza para los pronósticos (futuros valores de y)


















