
What is comparative modeling and why is it useful? Steps in CM (overview + some details) ...
51
What is comparative modeling and why is it useful? Steps in CM (overview + some details) Accuracy of comparative models Loop modeling CM and Structural Genomics Comparative Protein Structure Comparative Protein Structure Modeling Modeling Lecture 4.1 Lecture 4.1 Roberto Sanchez Structural Biology Program, Mount Sinai School of Medicine New York, NY 10029, USA [email protected]. edu http://physbio.mssm.edu/ ~sanchez/
-
Upload
janice-lawrence -
Category
Documents
-
view
222 -
download
0
Transcript of What is comparative modeling and why is it useful? Steps in CM (overview + some details) ...

What is comparative modeling and why is it useful?
Steps in CM (overview + some details)
Accuracy of comparative models
Loop modeling
CM and Structural Genomics
What is comparative modeling and why is it useful?
Steps in CM (overview + some details)
Accuracy of comparative models
Loop modeling
CM and Structural Genomics
Comparative Protein Structure ModelingComparative Protein Structure Modeling
Lecture 4.1Lecture 4.1Roberto Sanchez
Structural Biology Program,
Mount Sinai School of Medicine
New York, NY 10029, USA
http://physbio.mssm.edu/~sanchez/

Function via Structure
Structure Function
GFCHIKAYTRLIM…
Sequence

Why is it useful to know the structure of a protein Why is it useful to know the structure of a protein not only its sequence?not only its sequence?
The biochemical function (activity) of a protein is defined by its interaction with The biochemical function (activity) of a protein is defined by its interaction with other molecules. other molecules.
The biological function is in large part a consequence of these interactions.The biological function is in large part a consequence of these interactions.
The 3D structure is more informative than sequence because interactions are The 3D structure is more informative than sequence because interactions are determined by residues that are determined by residues that are close in spaceclose in space but are frequently but are frequently distant in distant in sequencesequence..
In addition, since evolution tends to conserve In addition, since evolution tends to conserve function and function depends more directly function and function depends more directly on structure than on sequence, on structure than on sequence, structure is structure is more conserved in evolution than sequencemore conserved in evolution than sequence..
The net result is that The net result is that patterns in spacepatterns in space are are frequently frequently more recognizablemore recognizable than patterns in than patterns in sequencesequence..

Why Protein Structure Prediction?Why Protein Structure Prediction?
• Known Sequences Known Sequences (5/30/01) (5/30/01) : : 694,000694,000
• Known Structures Known Structures (5/29/01)(5/29/01) : : 15,20015,200
We know the experimental 3D structure for less We know the experimental 3D structure for less than 3% of the protein sequences.than 3% of the protein sequences.
For the remaining 97% we need some sort of 3D For the remaining 97% we need some sort of 3D structure prediction.structure prediction.

What is Comparative Protein Structure Modeling?What is Comparative Protein Structure Modeling?
Protein Structure PredictionProtein Structure Prediction
…SDVIFTEDGILICNRK…

Principles of Protein Structure
GFCHIKAYTRLIMVG…
Folding
An
ab
ae
na
7120
An
ac
ys
tis n
idu
lan
s
Co
nd
rus
cris
pu
s
De
su
lfov
ibrio
vu
lga
ris
EvolutionAb initio prediction Fold Recognition
Comparative Modeling

Steps in Comparative Protein Structure ModelingSteps in Comparative Protein Structure Modeling
Target – TemplateAlignment
Target – TemplateAlignment
MSVIPKRLYGNCEQTSEEAIRIEDSPIV---TADLVCLKIDEIPERLVGEASILPKRLFGNCEQTSDEGLKIERTPLVPHISAQNVCLKIDDVPERLIPE
Model BuildingModel Building
STARTSTART
ASILPKRLFGNCEQTSDEGLKIERTPLVPHISAQNVCLKIDDVPERLIPERASFQWMNDK
TARGET
Template SearchTemplate Search
TEMPLATE
No
Model EvaluationModel Evaluation
OK?OK?
ENDEND
Yes
A. Šali, Curr. Opin. Biotech. 6, 437, 1995.R. Sánchez & A. Šali, Curr. Opin. Str. Biol. 7, 206, 1997.M. Marti et al. Ann. Rev. Biophys. Biomolec. Struct., 29, 291, 2000.

Template Search Methods
Sequence similarity searchesSequence similarity searches (B(BLASTLAST, FastA), FastA)
Profile and iterative methodsProfile and iterative methods (HMMs, P(HMMs, PSISI-B-BLASTLAST))
Structure based threadingStructure based threading (T(THREADERHREADER, P, PROFITROFIT))

Target – Template Alignment Methods
Dynamic Programming Pairwise AlignmentsDynamic Programming Pairwise Alignments Multiple Alignments, Profiles, HMMsMultiple Alignments, Profiles, HMMs Structure based approaches (Threading)Structure based approaches (Threading)

Model Building Methods
Rigid Body AssemblyRigid Body Assembly (C(COMPOSEROMPOSER)) Segment MatchingSegment Matching (S(SEGEGMMODOD)) Satisfaction of Spatial RestraintsSatisfaction of Spatial Restraints (M(MODELLERODELLER))
A. Šali, Curr. Opin. Biotech. 6, 437, 1995R. Sánchez & A. Šali, Curr. Opin. Str. Biol. 7, 206, 1997

Comparative Modeling by MComparative Modeling by MODELLERODELLER
3D GKITFYERGFQGHCYESDC-NLQPSEQ GKITFYERG---RCYESDCPNLQP
EXTRACT Spatial Restraints
F(R) = pi(fi/I)i
SATISFY Spatial Restraints
A. Šali & T. Blundell, J. Mol. Biol. 234, 779, 1993 http://guitar.rockefeller.edu/modeller/

Model Evaluation methods
StereochemistryStereochemistry (P(PROCHECKROCHECK)) EnvironmentEnvironment (Profiles3D)(Profiles3D) Statistical potentials based methodsStatistical potentials based methods (P(PROSAROSAII)II)

Model Evaluation: Alignment ErrorsModel Evaluation: Alignment Errors
R. Sánchez & A. Šali, Proteins, Suppl. 1, 50-58, 1997

Are models useful if they are just copies of the template?

Do mast cell proteases bind proteoglycans? Where? When?
1. mMCPs bind negatively charged proteoglycans through electrostatic interactions?
2. Comparative models used to find clusters of positively charged surface residues.
3. Tested by site-directed mutagenesis..
Huang et al. J. Clin. Immunol. 18,169,1998.Matsumoto et al. J.Biol.Chem. 270,19524,1995.Šali et al. J. Biol. Chem. 268, 9023, 1993.
Native mMCP-7 at pH=5 (His+
) Native mMCP-7 at pH=7 (His0)
Predicting features of a model that are not present in the templatePredicting features of a model that are not present in the template

Model Accuracy

Typical Errors in Comparative Models
Distortion in correctly
aligned regions
Region without a
template
Sidechain packing
Incorrect template
MODEL
X-RAY
TEMPLATE
Misalignment

CASP: CASP: Lessons from Blind PredictionsLessons from Blind Predictions
• Build models for proteins of unknown structure.Build models for proteins of unknown structure.
• Structures are determined after the models are Structures are determined after the models are submitted.submitted.
• Models are evaluated by comparing them with Models are evaluated by comparing them with the corresponding experimental structures.the corresponding experimental structures.

CASP: CASP: Lessons from Blind PredictionsLessons from Blind Predictions
Multiple Template ModelsMultiple Template Models
• Comparative modeling (by MComparative modeling (by MODELLERODELLER) can ) can combine the best regions from each template.combine the best regions from each template.
• The per-residue accuracy of comparative The per-residue accuracy of comparative models can not be higher than that of any of the models can not be higher than that of any of the templates.templates.
• The overall accuracy of models can be higher The overall accuracy of models can be higher than that of any of the templates.than that of any of the templates.

R. Sánchez & A. Šali, Proteins, Suppl. 1, 50-58, 1997
CASP: CASP: Lessons from Blind Predictions (DFR)Lessons from Blind Predictions (DFR)

Model Accuracy as a Function of Target-Template Sequence Identity
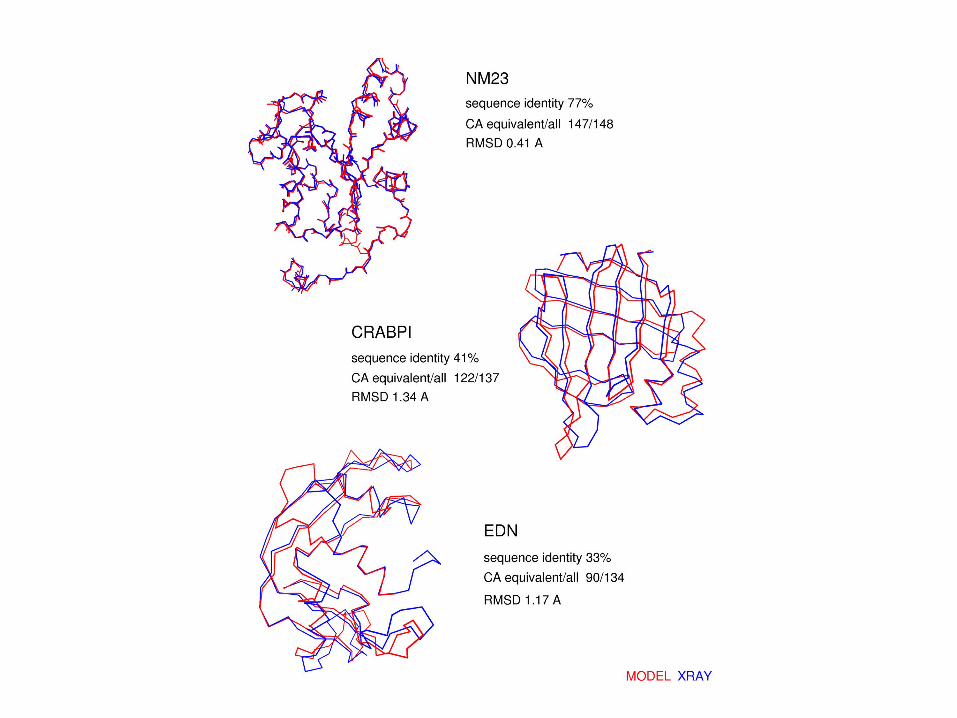

Some Models Can Be Surprisingly Accurate Some Models Can Be Surprisingly Accurate (in Some Regions)(in Some Regions)
24% sequence identity
YJL001W1rypH
25% sequence identity
YGL203C1ac5
Ser 176
His 488
Asp 383


Applications of Comparative Models

barrel: flavodoxin
antiparallel -barrel
IG fold: immunoglobulin
Loop Modeling in Protein Structures
A. Fiser, R. Do & A. Šali, Prot. Sci., 9, 1753, 2000
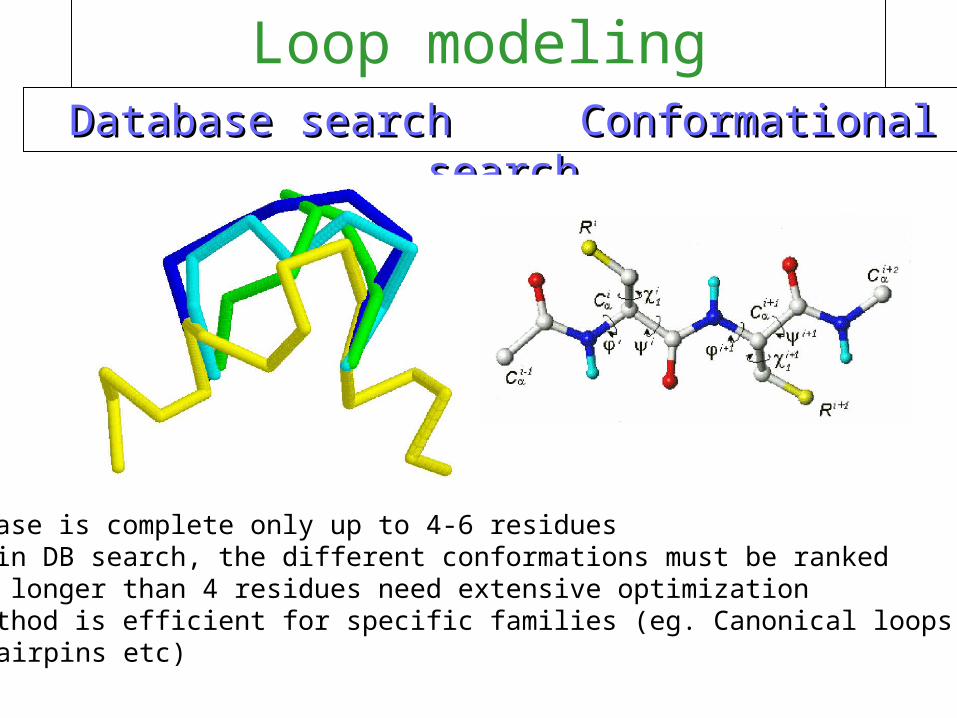
Loop modeling strategiesDatabase search Conformational searchDatabase search Conformational search
• database is complete only up to 4-6 residues• even in DB search, the different conformations must be ranked- loops longer than 4 residues need extensive optimization- DB method is efficient for specific families (eg. Canonical loops in Ig’s,
hairpins etc)

Loop Modeling by Conformational Search
1. Protein representation.
2. Energy (scoring) function.
3. Optimization algorithm.
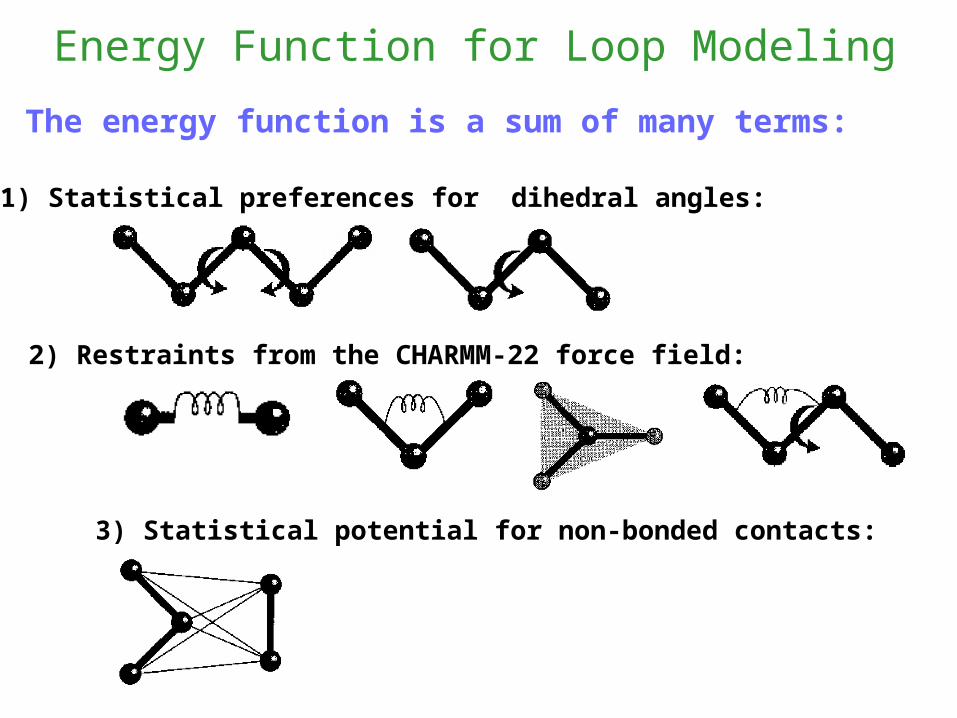
Energy Function for Loop Modeling
The energy function is a sum of many terms:
1) Statistical preferences for dihedral angles:
2) Restraints from the CHARMM-22 force field:
3) Statistical potential for non-bonded contacts:
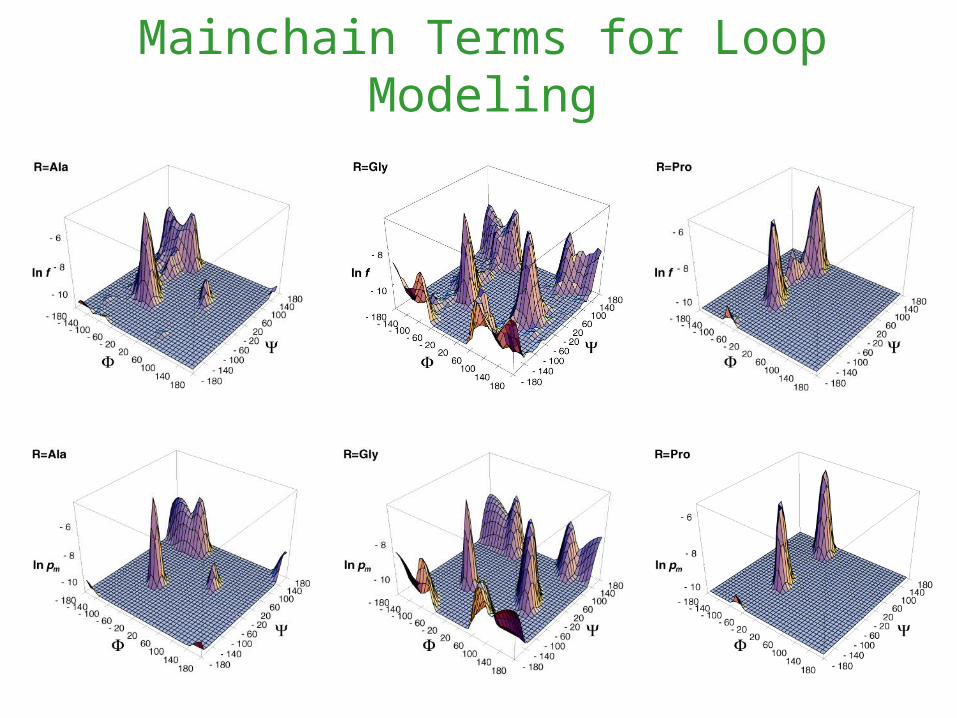
Mainchain Terms for Loop Modeling

Optimization of Objective Function

Calculating an Ensemble of Loop Models

Accuracy of loop models

Assessing Accuracy of Loop Models

Accuracy of Loop Modeling
RMSD=0.6Å
HIGH ACCURACY (<1Å)
50% (30%) of 8-residue loops
RMSD=1.1Å
MEDIUM ACCURACY (<2Å)
40% (48%) of 8-residue loops
RMSD=2.8Å
LOW ACCURACY (>2Å)
10% (22%) of 8-residue loops
A. Fiser, R. Do & A. Šali, Prot. Sci., 9, 1537, 2000

Fraction of Loops Modeled With at Least Medium Accuracy

T0058: 80-85RMSDmnch loop = 1.09 ÅRMSDmnch anchors = 0.29 Å
Problems in Practical Loop Modeling
1. Decide which regions to model as loops.2. Correct alignment of anchor regions & environment.3. Modeling of a loop.
T0076: 46-53RMSDmnch loop = 1.37 ÅRMSDmnch anchors = 1.52 Å

How can Comparative Modeling be used in Structural Genomics?

Structural Genomics
Definition:Definition: The aim of structural genomics is to put every The aim of structural genomics is to put every protein sequence within a modeling distance of a known protein sequence within a modeling distance of a known protein structure.protein structure.
Size of the problem:Size of the problem:There are a few thousand domain fold families.There are a few thousand domain fold families.There are ~20,000 sequence families (30% sequence id).There are ~20,000 sequence families (30% sequence id).
Solution:Solution: Determine many protein structures.Determine many protein structures.Increase modeling distance. Increase modeling distance.
Šali. Nat. Struct. Biol. 5, 1029, 1998. Burley et al. Nat. Genet. 23, 151, 1999.Šali & Kuriyan. TIBS 22, M20, 1999. Sanchez et al. Nat. Str. Biol. 7, 986, 2000

How can Comparative Modeling be used in Structural Genomics?
• Target SelectionTarget Selection
How many structures need to be solved?Which structures should we solve first?
• Target AmplificationTarget Amplification
How much of the sequence space is covered by: • a new structure• all structures

Target Selection for Structural Genomics
Select targets such that every Select targets such that every protein sequence is withinprotein sequence is within a a modeling distancemodeling distance of a known of a known protein structure.protein structure.
Modeling distance: correct alignment, corresponding to >30% sequence identity.
G. Kurban, R. Sánchez, A. Šali, T. Gaasterland.

Leveraging Templates by Comparative ModelingQuantifying Productivity of Structural Genomics
Modeling Modeling TemplateTemplate
Models + Fold Models + Fold AssignmentsAssignments
Reliable Reliable ModelsModels
Accurate Accurate ModelsModels
Less Less Accurate Accurate ModelsModels
Fold Fold AssignmentsAssignments
P007P007 2727 2727 1919 99 00
P008P008 1818 1818 1111 77 00
P018P018 108108 3232 33 2929 7676
P100P100 2626 1212 55 77 1414
TotalTotal 179179 8989 3838 5151 9090
http://www.nysgrc.org
Models are in MODBASE at http://guitar.rockefeller.edu/modbase/

START
Prepare PSI-BLAST PSSM by comparing the sequence against the NR database of sequences
Use the sequence PSSM to search against the
representative set of PDB chains (F and no-F)
Use the PDB chain PSSMs to search against the
sequence (F and no-F)
PS
I-B
LA
ST
PS
I-B
LA
ST
MMODODPPIPE:IPE: Large-Scale Comparative Protein Structure Modeling Large-Scale Comparative Protein Structure Modeling
Select Templates using a permissive E-value
cutoff
Build a model for the target segment by satisfaction of spatial
restraints
Evaluate the model
Align the matched part of the target sequence with the template
structure
MO
DE
LL
EM
OD
EL
LE
RR
1
1
For each
For each
sequencesequence
END
For each
For each
template
template
R. Sánchez & A. Šali, Proc. Natl. Acad. Sci. USA 95, 13597, 1998R. Sánchez, F. Melo, N. Mirkovic, A. Šali, in preparation
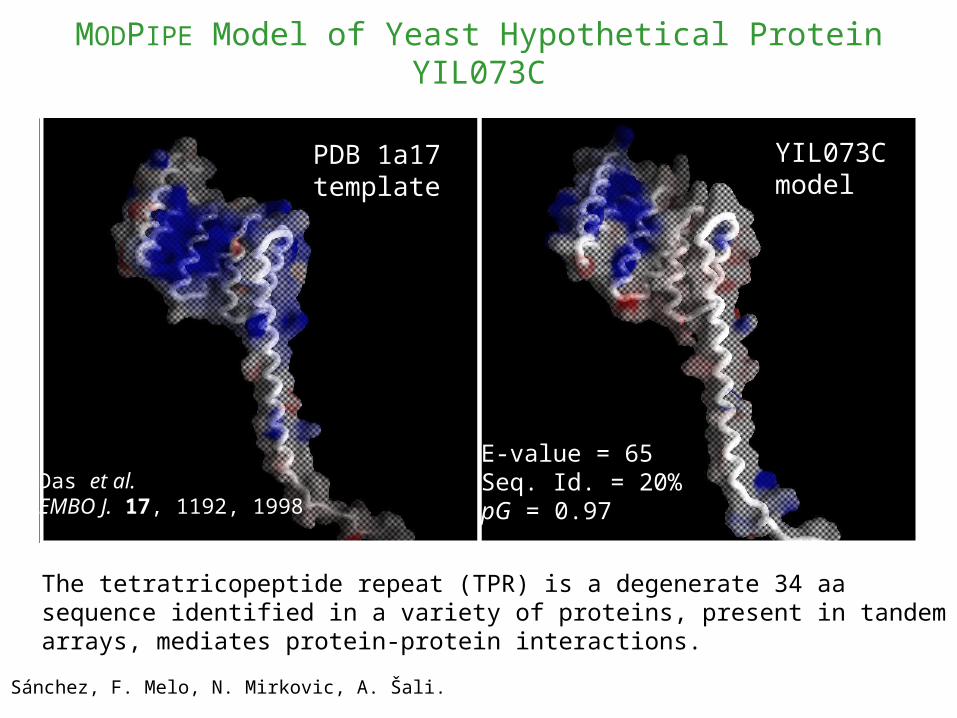
MODPIPE Model of Yeast Hypothetical Protein YIL073C
R. Sánchez, F. Melo, N. Mirkovic, A. Šali.
PDB 1a17 template
YIL073Cmodel
Das et al. EMBO J. 17, 1192, 1998
E-value = 65Seq. Id. = 20%pG = 0.97
The tetratricopeptide repeat (TPR) is a degenerate 34 aa sequence identified in a variety of proteins, present in tandem arrays, mediates protein-protein interactions.
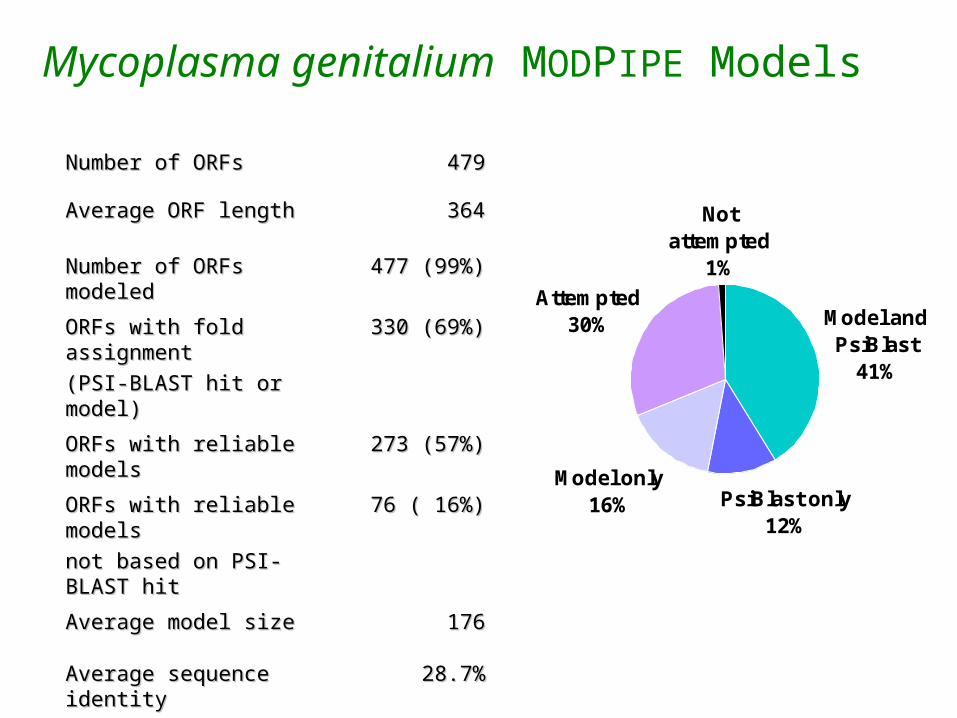
Mycoplasma genitalium MODPIPE Models
Number of ORFsNumber of ORFs 479479
Average ORF lengthAverage ORF length 364364
Number of ORFs modeledNumber of ORFs modeled 477 (99%)477 (99%)
ORFs with fold assignmentORFs with fold assignment
(PSI-BLAST hit or model)(PSI-BLAST hit or model)
330 (69%)330 (69%)
ORFs with reliable modelsORFs with reliable models 273 (57%)273 (57%)
ORFs with reliable modelsORFs with reliable models
not based on PSI-BLAST hitnot based on PSI-BLAST hit
76 ( 16%)76 ( 16%)
Average model sizeAverage model size 176176
Average sequence identityAverage sequence identity 28.7%28.7%
PsiBlast only12%
Model only16%
Attempted30%
Not attempted
1%
Model and PsiBlast
41%
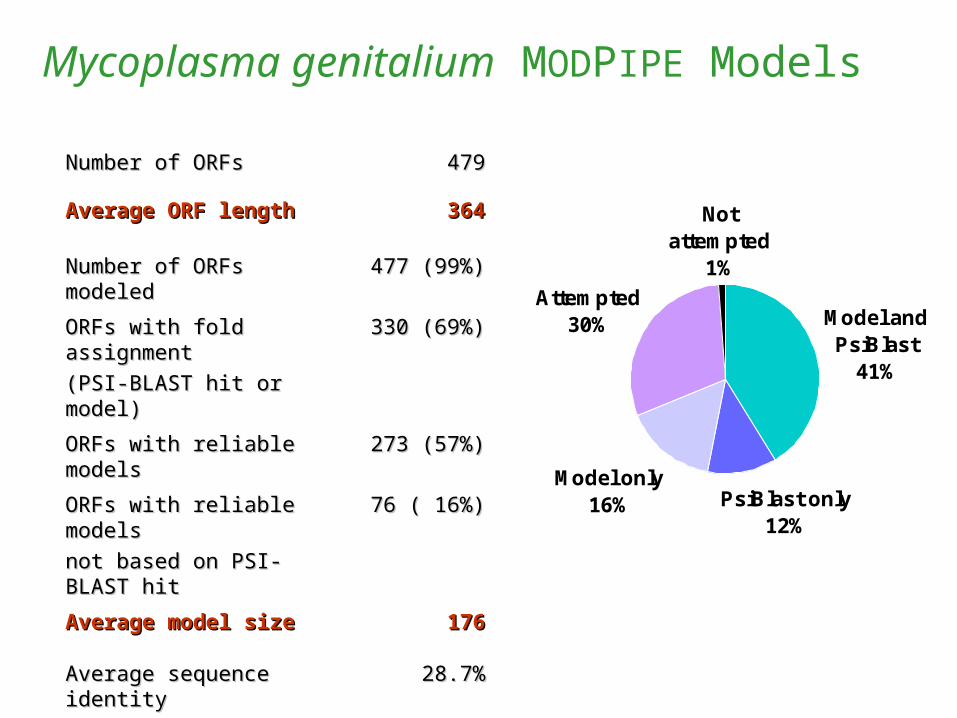
Mycoplasma genitalium MODPIPE Models
Number of ORFsNumber of ORFs 479479
Average ORF lengthAverage ORF length 364364
Number of ORFs modeledNumber of ORFs modeled 477 (99%)477 (99%)
ORFs with fold assignmentORFs with fold assignment
(PSI-BLAST hit or model)(PSI-BLAST hit or model)
330 (69%)330 (69%)
ORFs with reliable modelsORFs with reliable models 273 (57%)273 (57%)
ORFs with reliable modelsORFs with reliable models
not based on PSI-BLAST hitnot based on PSI-BLAST hit
76 ( 16%)76 ( 16%)
Average model sizeAverage model size 176176
Average sequence identityAverage sequence identity 28.7%28.7%
PsiBlast only12%
Model only16%
Attempted30%
Not attempted
1%
Model and PsiBlast
41%

Factors affecting coverage:Factors affecting coverage: PDB growthPDB growth
Fold assignments
Reliable models

Organism Statistics
OrganismOrganism # sequences# sequences # models# models models/models/
seq#seq#
# CATH # CATH
foldsfolds
Homo sapiensHomo sapiens 13,78513,785 37,63837,638 2.732.73 315315
HIV type 1HIV type 1 25,65425,654 33,18033,180 1.291.29 1212
D. melanogasterD. melanogaster 8,2488,248 25,31425,314 3.063.06 299299
C. elegansC. elegans 7,2607,260 20,09520,095 2.762.76 289289
A. thalianaA. thaliana 8,8528,852 18,69518,695 2.112.11 294294
Mus musculusMus musculus 6,2326,232 17,24817,248 2.762.76 271271
R. norvegicusR. norvegicus 3,5863,586 9,2999,299 2.592.59 246246
S. cerevisiaeS. cerevisiae 2,5802,580 5,7495,749 2.222.22 237237
S. PombeS. Pombe 2,3152,315 4,4974,497 1.941.94 221221
E. coliE. coli 2,8622,862 4,3334,333 1.511.51 259259
Top 10 organism by number of models
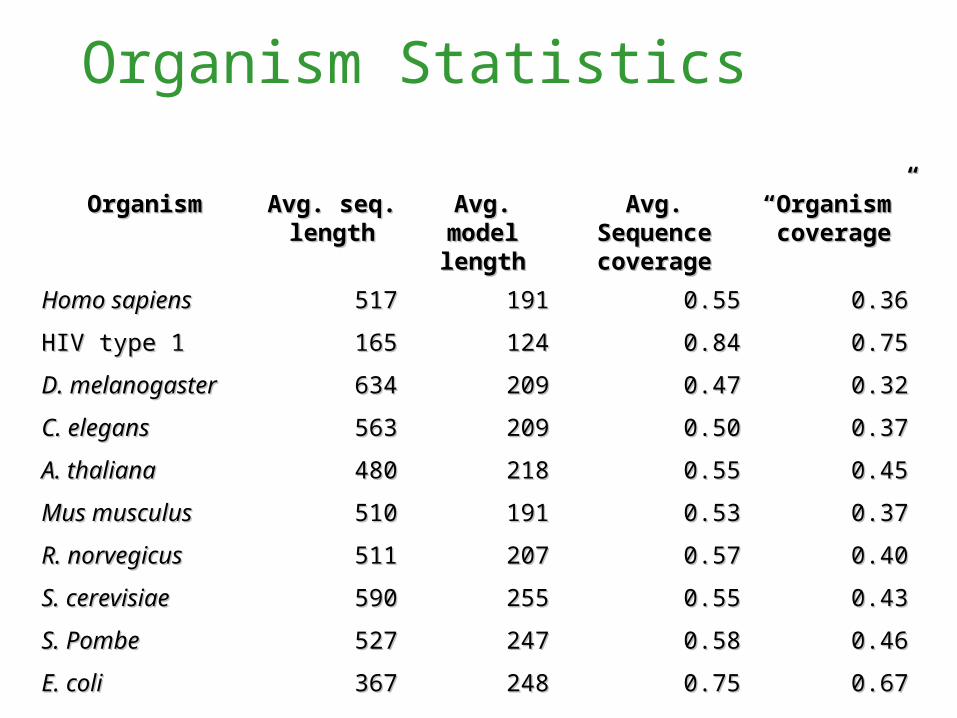
Organism Statistics
OrganismOrganism Avg. seq. Avg. seq. lengthlength
Avg. model Avg. model lengthlength
Avg. Sequence Avg. Sequence coveragecoverage
““Organism” Organism” coveragecoverage
Homo sapiensHomo sapiens 517517 191191 0.550.55 0.360.36
HIV type 1HIV type 1 165165 124124 0.840.84 0.750.75
D. melanogasterD. melanogaster 634634 209209 0.470.47 0.320.32
C. elegansC. elegans 563563 209209 0.500.50 0.370.37
A. thalianaA. thaliana 480480 218218 0.550.55 0.450.45
Mus musculusMus musculus 510510 191191 0.530.53 0.370.37
R. norvegicusR. norvegicus 511511 207207 0.570.57 0.400.40
S. cerevisiaeS. cerevisiae 590590 255255 0.550.55 0.430.43
S. PombeS. Pombe 527527 247247 0.580.58 0.460.46
E. coliE. coli 367367 248248 0.750.75 0.670.67
Top 10 organism by number of models

MODBASE
R. Sánchez, U. Pieper, N.Mirkovic, P. I. W. de Bakker, E. Wittenstein, and A. Šali. Nucl. Acids Res., 28, 250. 2000
R. Sánchez and A. Šali. Bioinformatics, 15, 1060, 1999

ReviewComparative models can help in understanding the function of proteins Comparative models can help in understanding the function of proteins by:by:
Detecting remote structural (functional?) relationships.Detecting remote structural (functional?) relationships.Revealing features that are not present in the templates.Revealing features that are not present in the templates.Revealing features that are not recognizable from the sequence.Revealing features that are not recognizable from the sequence.
Insertions (loops) up to 8 residues long can be reliable modeled.Insertions (loops) up to 8 residues long can be reliable modeled.
Comparative modeling can play a role in structural genomics: in target Comparative modeling can play a role in structural genomics: in target selection and in amplifying the experimental data.selection and in amplifying the experimental data.
At present, useful 3D models can be obtained for domains in At present, useful 3D models can be obtained for domains in approximately 50% of the proteins (25% of domains), because we approximately 50% of the proteins (25% of domains), because we improved our improved our techniquestechniques and because of the many and because of the many known protein known protein structuresstructures and and sequencessequences..


















