
Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007 1 Principles of...
46
1 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007 Principles of Reliable Distributed Systems Lecture 9: Paxos Spring 2007 Prof. Idit Keidar
-
date post
19-Dec-2015 -
Category
Documents
-
view
216 -
download
0
Transcript of Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007 1 Principles of...

1 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Principles of Reliable Distributed Systems
Lecture 9: Paxos
Spring 2007
Prof. Idit Keidar

2 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Material
• Paxos Made SimpleLeslie LamportACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) 18-25.

3 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Issues in the Real World I/III
• Problem: Sometimes messages take longer than expected
• Solution 1: Use longer timeouts– Slow convergence
• Solution 2: Assume asynchrony– FLP
• Solution 3: Assume eventual synchrony or unreliable failure detectors– See last week – MR Algorithm

4 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Issues in the Real World II/III
• Problem: Sometimes messages are lost• Solution 1: Use retransmissions
– In case of transient partitions, a huge backlog can build up – catching up may take forever
– More congestion, long message delays for extensive periods
• Solution 2: Allow message loss– 2 Generals
• Solution 3: Assume eventually reliable links– That’s what we’ll do today

5 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Issues in the Real World III/III
• Problem: Processes may crash and later recover (aka crash-recovery model)
• Solution 1: Store information on stable storage (disk) and retrieve it upon recovery– What happens to messages arriving when
they’re down?– See previous slide

6 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
MR and Unreliable Links
• From MR Algorithm Phase II:wait for (r,e) from n-t processes
• Transient message loss violates liveness
• What if we move to the next round in case we can’t get n-t responses for too long?– Notice the next line in MR:
if any non- value e received then val e
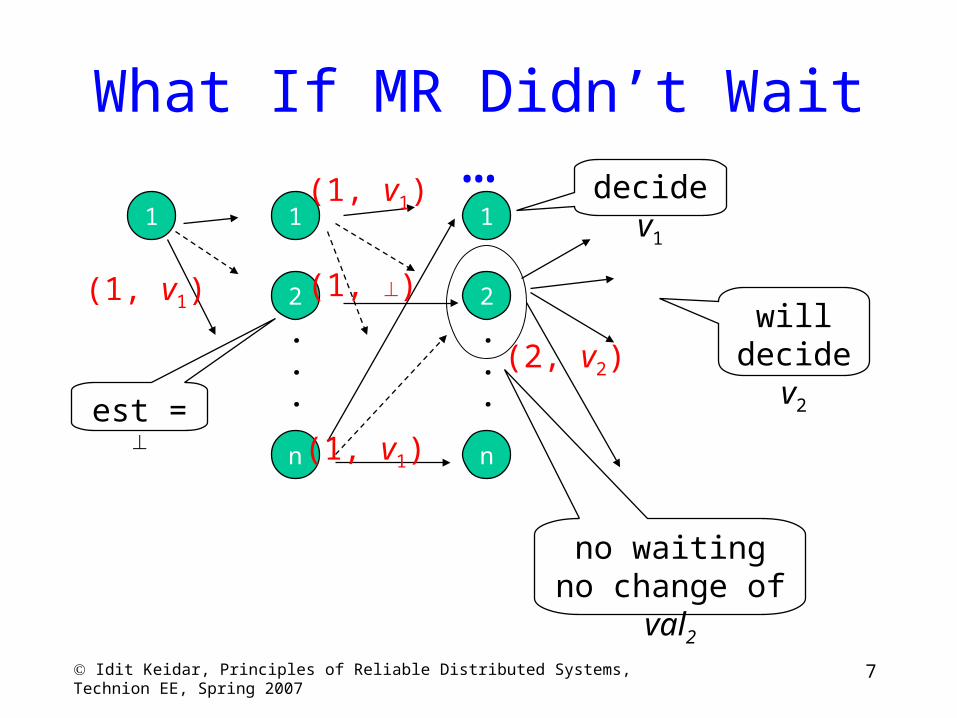
7 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
What If MR Didn’t Wait …1 1
2
n
.
.
.
(1, v1)
1
2
n
.
.
.
(1, v1)est =
(2, v2)
no waitingno change of val2
(1, v1) decide v1
(1, )will
decide v2

8 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
What Did We Learn?
• Do not get stuck in a round– Move on upon timeout– Move on upon hearing that others moved on
• But, a new leader before proposing a decision value
must learn any possibly decided value
(must check with a majority)

9 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos: Main Principles
• Use “leader election” module– If you think you’re leader, you can start a new “ballot”
• Paxos name for a round
• Always join the newest ballot you hear about– Leave old ballots in the middle if you need to
• Two phases:– First learn outcomes of previous ballots from a majority
– Then propose a new value, and get a majority to endorse it

10 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Leader Election Failure Detector
– Leader – Outputs one trusted process– From some point, all correct processes trust the
same correct process
• Can easily implement ◊S• Is the weakest for consensus
[Chandra, Hadzilacos, Toueg 96]

11 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Implementations
• Easiest: use ◊P implementation– In eventual synchrony model– Output lowest id non-suspected process
is implementable also in some situations where ◊P isn’t
• Optimizations possible– Choose “best connected”, strongest, etc.

12 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos: The Practicality
• Overcomes message loss without retransmitting entire message history
• Tolerates crash and recovery
• Does not rotate through dead coordinators
• Used in replicated file systems– Frangipani – DEC, early 90s– Nowadays Microsoft

13 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Part-Time Parliament[Lamport 88,98,01]
Recent archaeological discoveries on the island of Paxos reveal that the parliament functioned despite the peripatetic propensity of its part-time legislators.
The legislators maintained consistent copies of the parliamentary record, despite their frequent forays from the chamber and the forgetfulness of their messengers.
The Paxon parliament’s protocol provides a new way of implementing the state-machine approach to the design of distributed systems.

14 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Annotation of TOCS 98 Paper
• This submission was recently discovered behind a filing cabinet in the TOCS editorial office.
• …the author is currently doing field work in the Greek isles and cannot be reached …
• The author appears to be an archeologist with only a passing interest in computer science.
• This is unfortunate; even though the obscure ancient Paxon civilization he describes is of little interest to most computer scientists, its legislative system is an excellent model for how to implement a distributed computer system in an asynchronous environment.

15 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Setting
• The data (ledger) is replicated at n processes (legislators)
• Operations (decrees) should be invoked (recorded) at each replica (ledger) in the same order
• Processes (legislators) can fail (leave the parliament)
• At least a majority of processes (legislators) must be up (present in the parliament) in order to make progress (pass decrees)– Why majority?

16 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Eventually Reliable Links
• There is a time after which every message sent by a correct process to a correct process eventually arrives
• Usual failure-detector-based algorithms do not work – Homework question

17 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Paxos () Atomic Broadcast Algorithm
• Leader based: each process has an estimate of who is the current leader
• To order an operation, a process sends it to its current leader
• The leader sequences the operation and launches a Consensus algorithm (Synod) to fix the agreement

18 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The (Synod) Consensus Algorithm
• Solves non-terminating consensus in asynchronous system– or consensus in a partial synchrony system– or consensus using an failure detector
• Overcomes transient crashes & recoveries and message loss – can be modeled as message loss

19 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Consensus Algorithm Structure
• Two phases• Leader contacts a majority in each phase• There may be multiple concurrent leaders • Ballots distinguish among values
proposed by different leaders– unique, locally monotonically increasing– correspond to rounds of ◊S-based algorithm [MR] – processes respond only to leader with highest ballot
seen so far

20 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Ballot Numbers
• Pairs num, process id n1, p1 > n2, p2
– if n1 > n2 – or n1=n2 and p1 > p2
• Leader p chooses unique, locally monotonically increasing ballot number – if latest known ballot is n, q– p chooses n+1, p

21 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Two Phases of Paxos
• Phase 1: prepare– If trust yourself by believe you are the leader)
• Choose new unique ballot number
• Learn outcome of all smaller ballots from majority
• Phase 2: accept– Leader proposes a value with his ballot number– Leader gets majority to accept its proposal– A value accepted by a majority can be decided

22 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos - Variables
BallotNumi, initially 0,0
Latest ballot pi took part in (phase 1)
AcceptNumi, initially 0,0
Latest ballot pi accepted a value in (phase 2)
AcceptVali, initially
Latest accepted value (phase 2)

23 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos Phase I: Prepare - Leader
• Periodically, until decision is reached do:
if leader (by ) thenBallotNum BallotNum.num+1, myId send (“prepare”, BallotNum) to all
• Goal: contact other processes, ask them to join this ballot, and get information about possible past decisions

24 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos Phase I: Prepare - Cohort
• Upon receive (“prepare”, bal) from iif bal BallotNum then
BallotNum bal
send (“ack”, bal, AcceptNum, AcceptVal) to i
This is a higher ballot than my current, I better
join it!
Tell the leader about my latest accepted value

25 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos Phase II: Accept - Leader
Upon receive (“ack”, BallotNum, b, val) from n-tif all vals = then myVal = initial valueelse myVal = received val with highest b send (“accept”, BallotNum, myVal) to all /* proposal */
The value accepted in the highest ballot might have been decided, better
propose this value

26 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos Phase II: Accept - Cohort
Upon receive (“accept”, b, v) if b BallotNum then
AcceptNum b; AcceptVal v /* accept proposal */send (“accept”, b, v) to all (first time only)
This is not from an old ballot

27 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos – Deciding
Upon receive (“accept”, b, v) from n-t
decide v
periodically send (“decide”, v) to all
Upon receive (“decide”, v)
decide v
Why don’t we ever “return”?
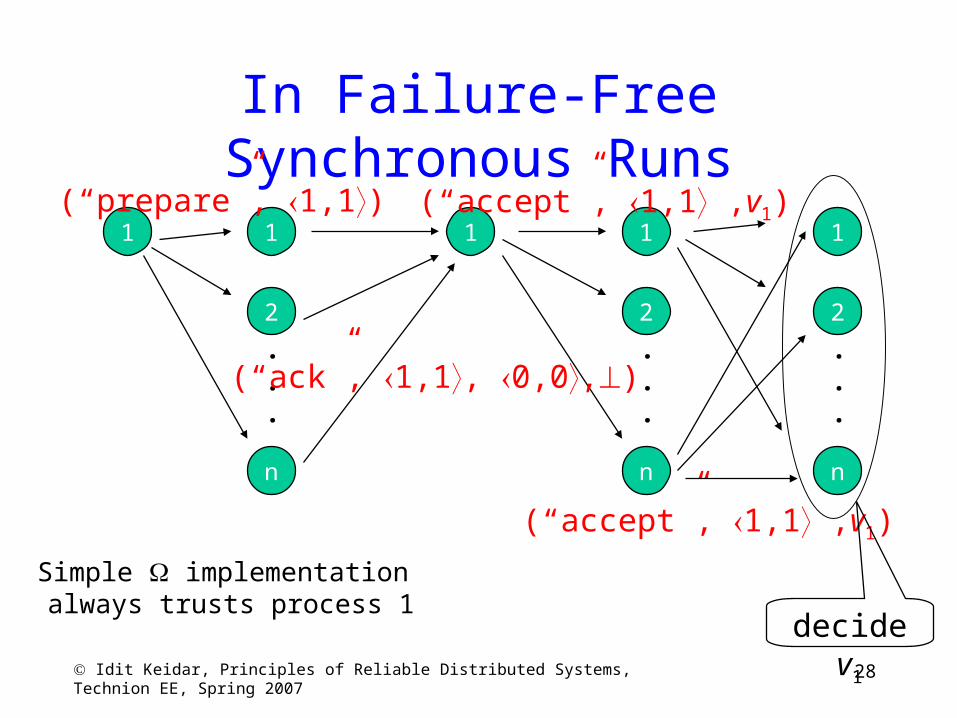
28 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
In Failure-Free Synchronous Runs
1 1
2
n
.
.
.
(“accept”, 1,1 ,v1)
1
2
n
.
.
.
1 1
2
n
.
.
.
(“prepare”, 1,1)
(“ack”, 1,1, 0,0,)
decide v1
(“accept”, 1,1 ,v1)
Simple implementation always trusts process 1

29 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Correctness: Agreement
• Follows from Lemma 1:If a proposal (b,v) is accepted by a majority of the processes, then for every proposal (b’, v’) with b’>b, it holds that v’=v.

30 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Proving Agreement Using Lemma 1
• Let v be a decided value. The first process that decides v receives n-t accept messages for v with some ballot b, i.e., (b,v) is accepted by a majority.
• No other value is accepted with the same b. Why?
• Let (b1,v1) be the first proposal accepted by n-t.
• By Lemma 1, v1 is the only possible decision value.

31 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
To Prove Lemma 1
• Use Lemma 2: (invariant):If a proposal (b,v) is sent, then there is a set S consisting of a majority such that either – no p in S accepts a proposal ranked less than b
(all vals = ; or– v is the value of the highest-ranked proposal
among proposals ranked less than b accepted by processes in S (myVal = received val with highest b).

32 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
To Prove Lemma 2
• A process can accept a proposal numbered b if and only if it has not responded to a prepare request having a number greater than b.
• The “ack” response to “prepare” is a promise not to accept lower-ballot proposals in the future.

33 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Termination
• Assume no loss for a moment.
• Once there is one correct leader –– It eventually chooses the highest ballot number– No other process becomes a leader with a
higher ballot – All correct processes “ack” its prepare message
and “accept” its accept message and decide

34 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
What About Message Loss?
• Does not block in case of a lost message– Phase 1 can start with new rank even if
previous attempts never ended
• Conditional liveness: If n-t correct processes including the leader can
communicate with each other then they eventually decide
• Holds with eventually reliable links

35 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Optimization
• Allow process 1 (only!) to skip Phase 1– Initiate BallotNum to 1,1 – Propose its own initial value
• 2 steps in failure-free synchronous runs
• 2 steps for repeated invocations with the same leader– Common case

36 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Atomic Broadcast by Running A Sequence of
Consensus Instances

37 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The Setting
• Data is replicated at n servers
• Operations are initiated by clients
• Operations need to be performed at all correct servers in the same order– state-machine replication

38 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Client-Server Interaction(Benign Version)
• Leader-based: each process (client/server) has an estimate of who is the current leader
• A client sends a request to its current leader
• The leader launches the Paxos consensus algorithm to agree upon the order of the request
• The leader sends the response to the client
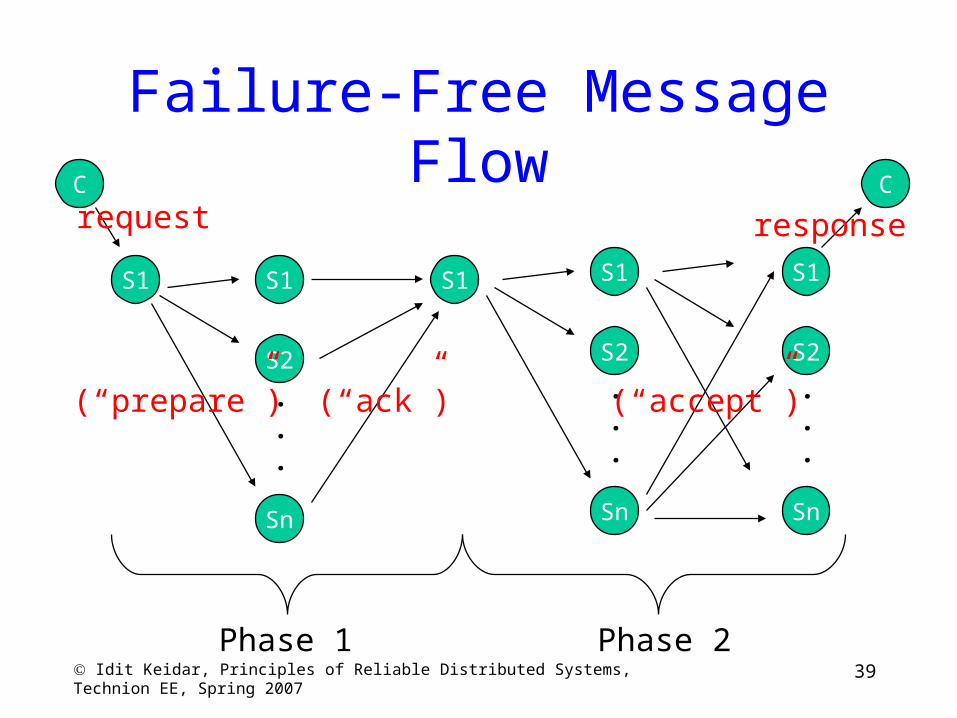
39 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Failure-Free Message Flow
S1S1 S1
S2
Sn
.
.
.
C
S1
S2
Sn
.
.
.
S1
S2
Sn
.
.
.
(“accept”)(“prepare”) (“ack”)
C
Phase 1 Phase 2
request response

40 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Observation
• In Phase 1, no consensus values are sent:– Leader chooses largest unique ballot number– Gets a majority to “vote” for this ballot number– Learns the outcome of all smaller ballots from
this majority
• In Phase 2, leader proposes either its own initial value or latest value it learned in Phase 1
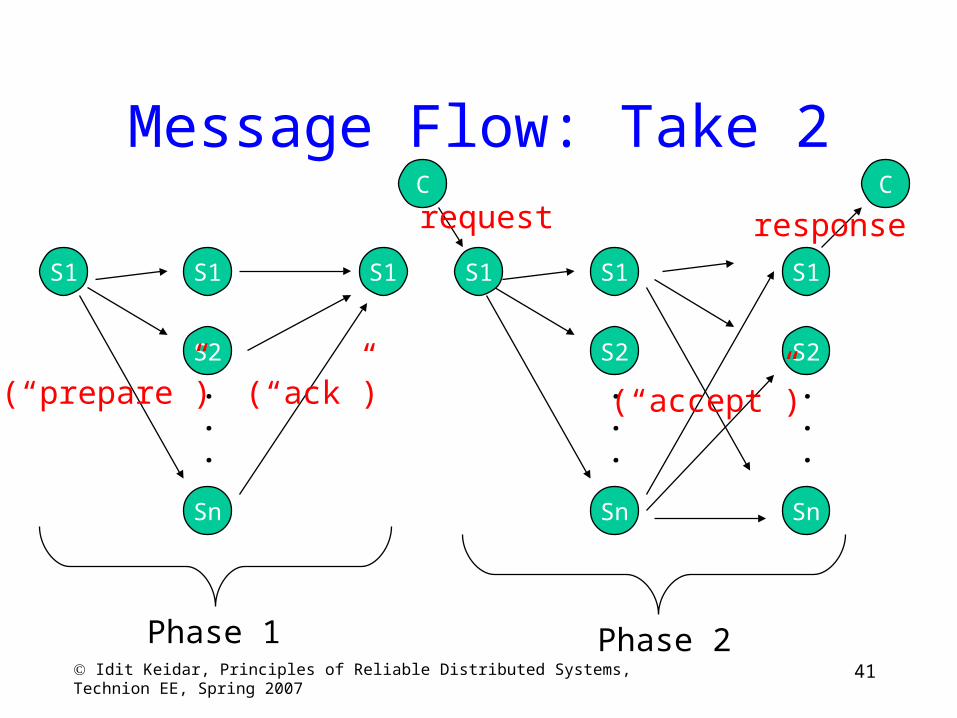
41 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Message Flow: Take 2
S1S1 S1
S2
Sn
.
.
.
C
S1
S2
Sn
.
.
.
S1
S2
Sn
.
.
.
(“accept”)(“prepare”) (“ack”)
C
Phase 1 Phase 2
request response
S1

42 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Optimization
• Run Phase 1 only when the leader changes– Phase 1 is called “view change” or “recovery mode”
– Phase 2 is the “normal mode”
• Each message includes BallotNum (from the last Phase 1) and ReqNum– e.g., ReqNum = 7 when we’re trying to agree what the
7th operation to invoke on the state machine should be
• Respond only to messages with the “right” BallotNum

43 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Paxos Atomic Broadcast: Normal Mode
Upon receive (“request”, v) from clientif (I am not the leader) then forward to leaderelse
/* propose v as request number n */ReqNum ReqNum +1; send (“accept”, BallotNum , ReqNum, v) to all
Upon receive (“accept”, b, n, v) with b = BallotNum
/* accept proposal for request number n */
AcceptNum[n] b; AcceptVal[n] v send (“accept”, b, n, v) to all (first time only)

44 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Recovery Mode
• The new leader must learn the outcome of all the pending requests that have smaller BallotNums– The “ack” messages include AcceptNums and
AcceptVals of all pending requests
• For all pending requests, the leader sends “accept” messages
• What if there are holes?– e.g., leader learns of request number 13 and not of 12
– fill in the gaps with dummy “do nothing” requests

45 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
Leslie Lamport’s Reflections
• Inspired by my success at popularizing the consensus problem by describing it with Byzantine generals, I decided to cast the algorithm in terms of a parliament on an ancient Greek island.
• To carry the image further, I gave a few lectures in the persona of an Indiana-Jones-style archaeologist.
• My attempt at inserting some humor into the subject was a dismal failure.

46 Idit Keidar, Principles of Reliable Distributed Systems, Technion EE, Spring 2007
The History of the Paperby Lamport
• I submitted the paper to TOCS in 1990. All three referees said that the paper was mildly interesting, though not very important, but that all the Paxos stuff had to be removed. I was quite annoyed at how humorless everyone working in the field seemed to be, so I did nothing with the paper.
• A number of years later, a couple of people at SRC needed algorithms for distributed systems they were building, and Paxos provided just what they needed. I gave them the paper to read and they had no problem with it. So, I thought that maybe the time had come to try publishing it again.


















