
Наивный байесовский классификатор. Дерево решений....
40
Наивный байесовский классификатор Дерево решений Случайный лес
-
Upload
bitworks-software -
Category
Data & Analytics
-
view
522 -
download
2
Transcript of Наивный байесовский классификатор. Дерево решений....

Наивный байесовский классификатор
Дерево решений
Случайный лес
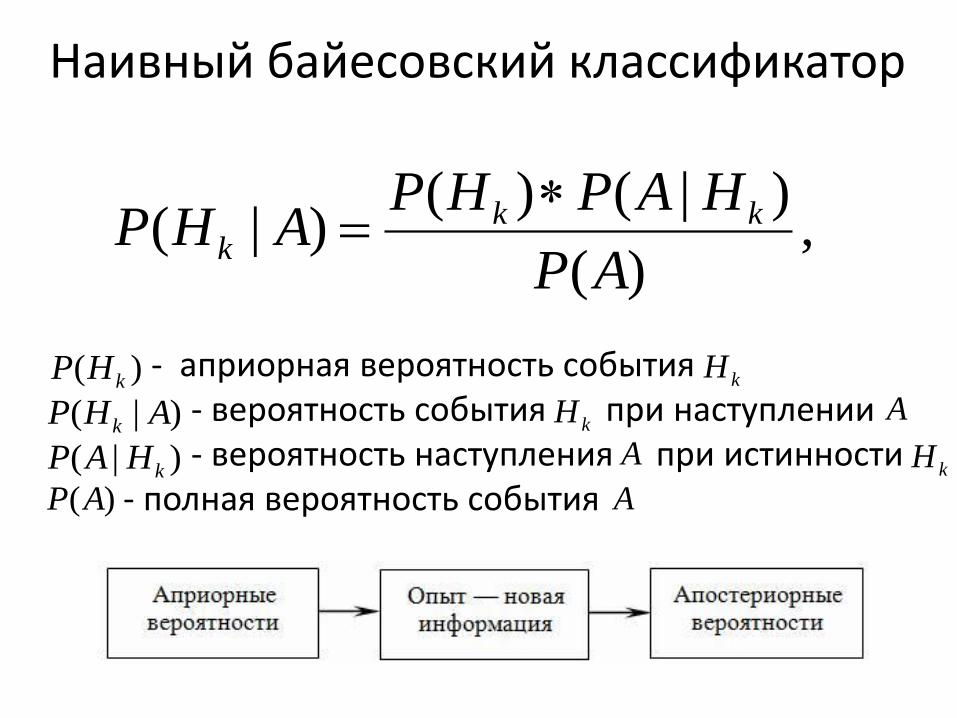
Наивный байесовский классификатор
,)(
)|()()|(
AP
HAPHPAHP kk
k
- априорная вероятность события - вероятность события при наступлении - вероятность наступления при истинности - полная вероятность события
)( kHP kH
)|( AHP k kH A
)(AP A
)|( kHAP AkH

От теории к практике
Имеется 3 урны. В первой 3 белых шара и 1 черный, во второй — 2 белых шара и 3 черных, в третьей — 3 белых шара.
Некто подходит наугад к одной из урн и вынимает из нее 1 шар. Этот шар оказался белым.
Найдите апостериорные вероятности того, что шар вынут из 1-й, 2-й, 3-й урны.

Области применения байесовского классификатора
• Классификация документов • Оценка риска мошенничества в деятельности гос.огранов • Идентификации мошенничества при подаче жалоб в сфере страхования • Для ранжирования покупателей в маркетинге

Дерево решений
В начале множество - это обучающая выборка. 1. Выбирается признак, по которому
множество разбивается на подмножества.
2. Переходим к каждому подмножеству и проверяем, если оно состоит из элементов, принадлежащих одной категории, то этот узел дерева становится листом. В противном случае переходим к первому шагу.
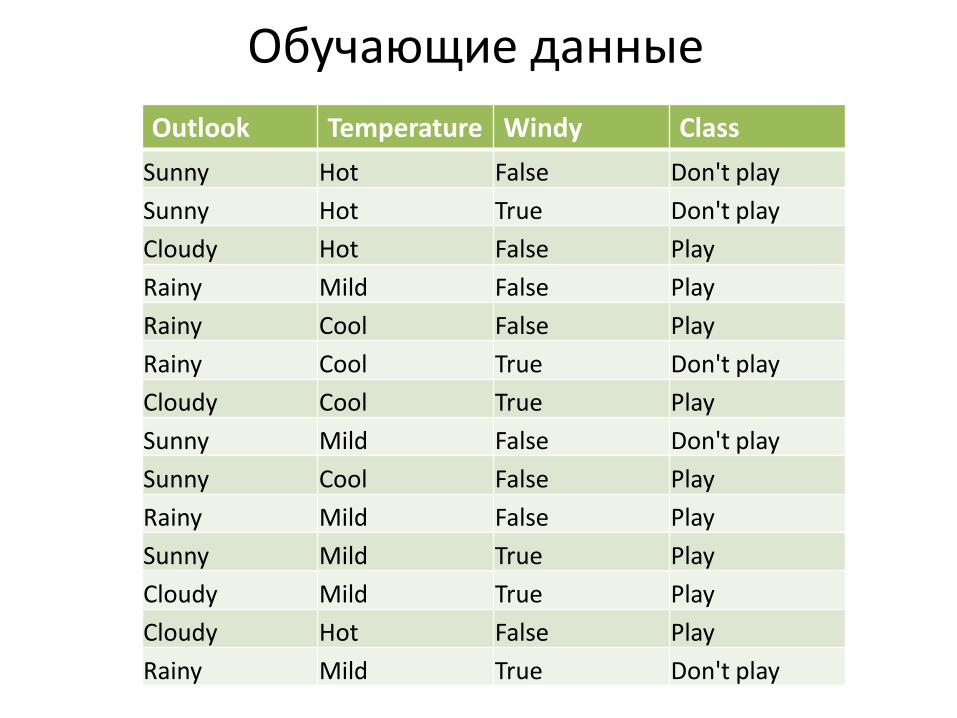
Обучающие данные
Outlook Temperature Windy Class
Sunny Hot False Don't play
Sunny Hot True Don't play
Cloudy Hot False Play
Rainy Mild False Play
Rainy Cool False Play
Rainy Cool True Don't play
Cloudy Cool True Play
Sunny Mild False Don't play
Sunny Cool False Play
Rainy Mild False Play
Sunny Mild True Play
Cloudy Mild True Play
Cloudy Hot False Play
Rainy Mild True Don't play
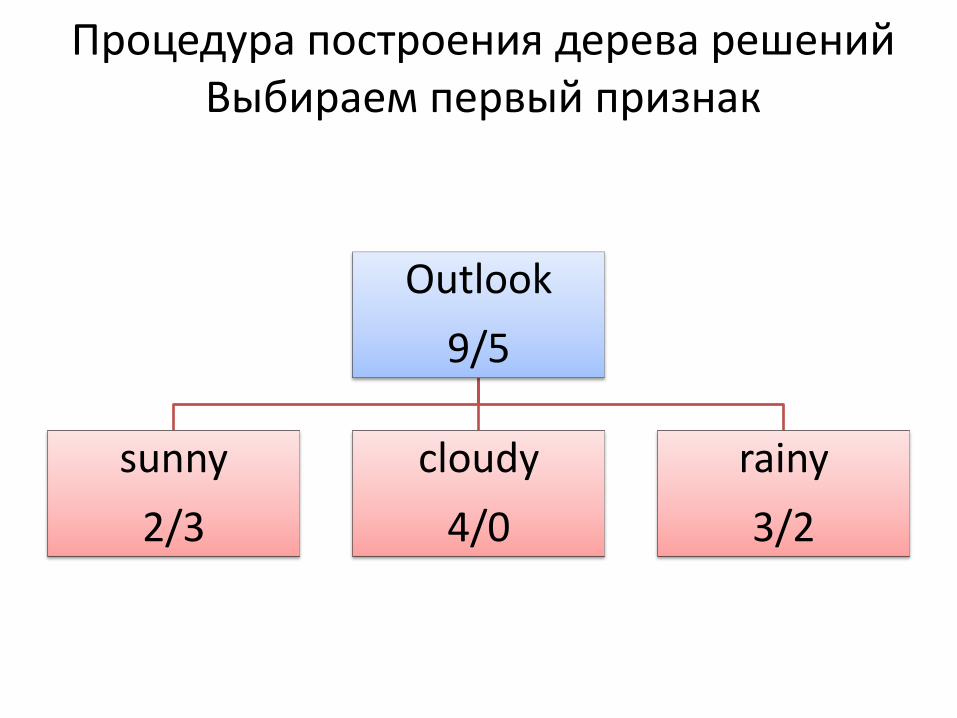
Процедура построения дерева решений Выбираем первый признак
Outlook
9/5
sunny
2/3
cloudy
4/0
rainy
3/2
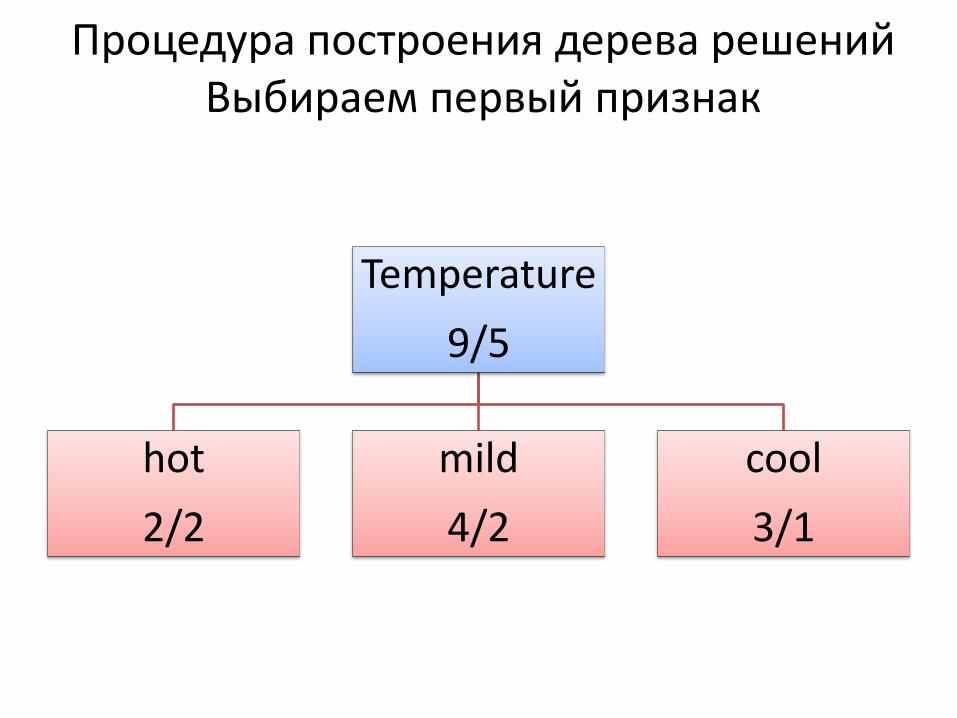
Процедура построения дерева решений Выбираем первый признак
Temperature
9/5
hot
2/2
mild
4/2
cool
3/1
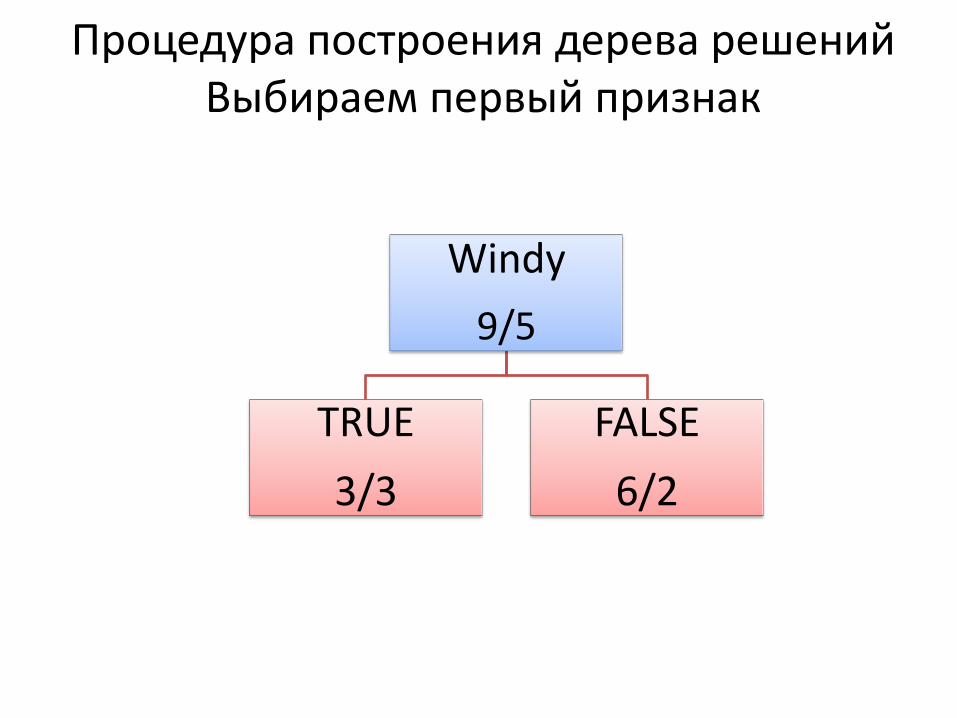
Процедура построения дерева решений Выбираем первый признак
Windy
9/5
TRUE
3/3
FALSE
6/2
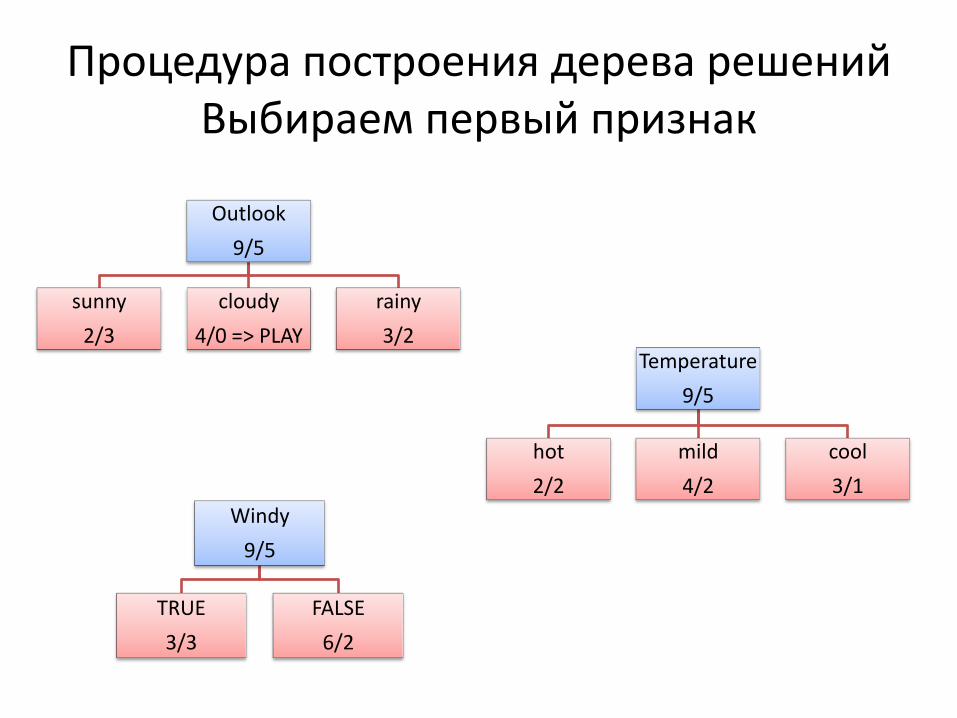
Процедура построения дерева решений Выбираем первый признак
Outlook
9/5
sunny
2/3
cloudy
4/0 => PLAY
rainy
3/2 Temperature
9/5
hot
2/2
mild
4/2
cool
3/1
Windy
9/5
TRUE
3/3
FALSE
6/2
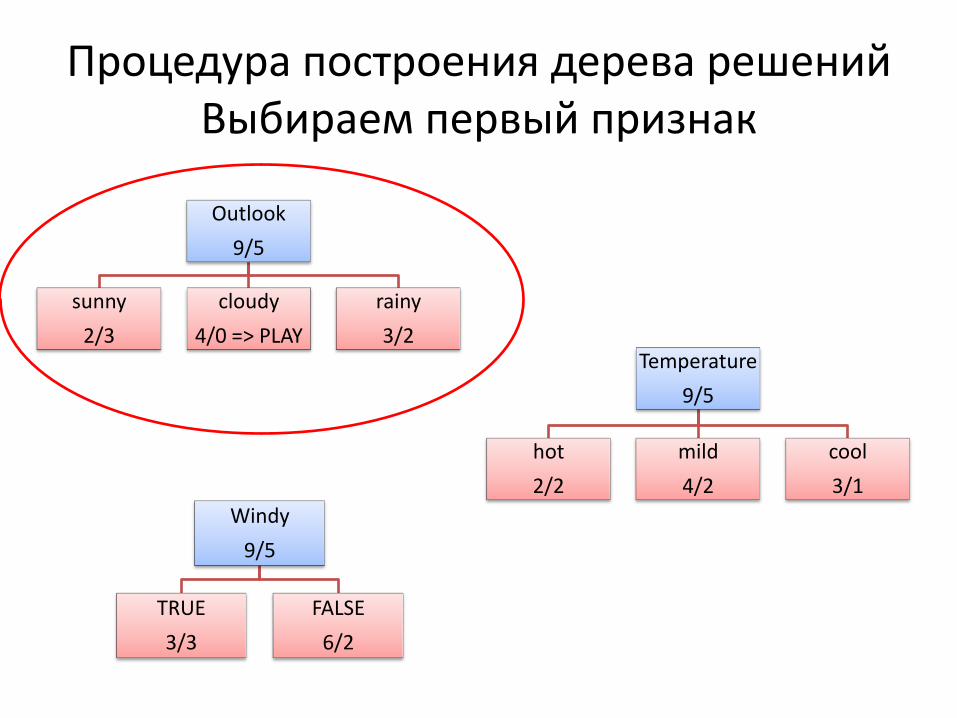
Процедура построения дерева решений Выбираем первый признак
Outlook
9/5
sunny
2/3
cloudy
4/0 => PLAY
rainy
3/2 Temperature
9/5
hot
2/2
mild
4/2
cool
3/1
Windy
9/5
TRUE
3/3
FALSE
6/2
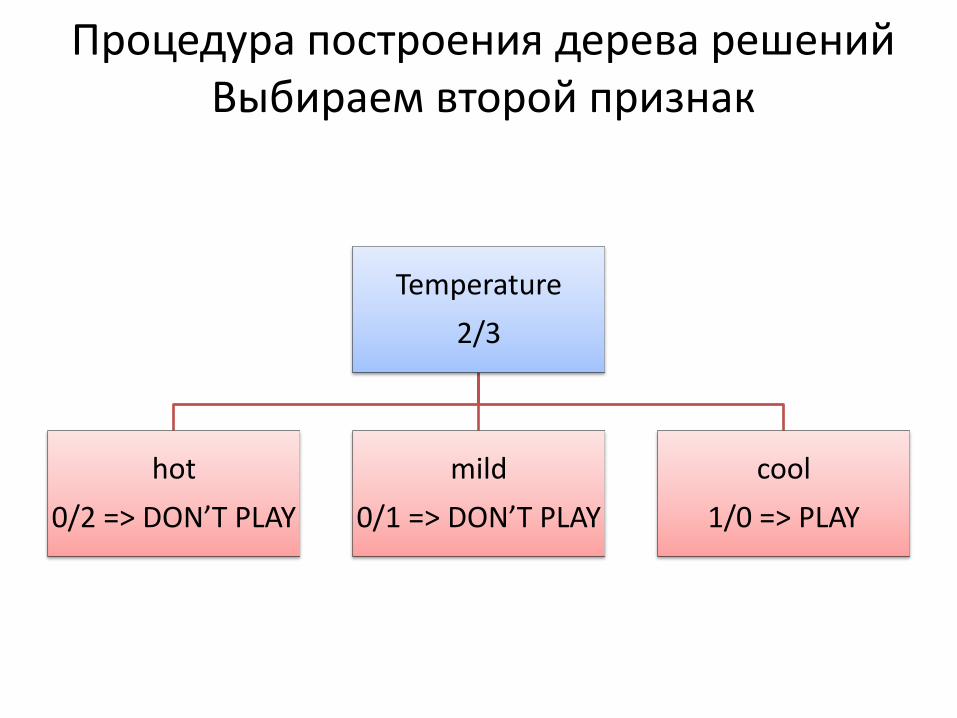
Процедура построения дерева решений Выбираем второй признак
Temperature
2/3
hot
0/2 => DON’T PLAY
mild
0/1 => DON’T PLAY
cool
1/0 => PLAY
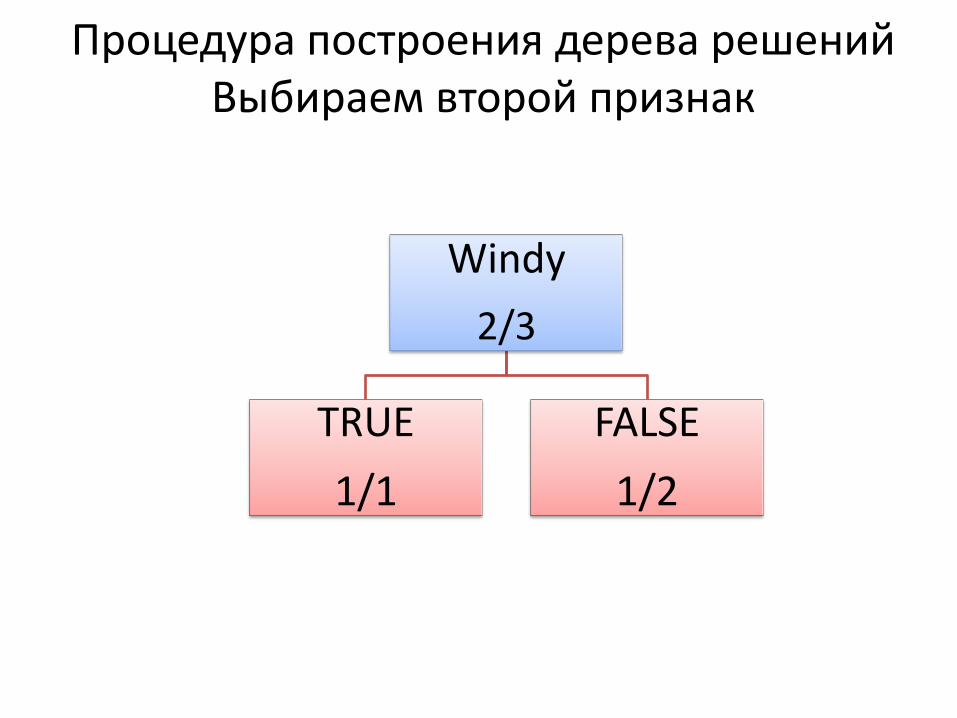
Процедура построения дерева решений Выбираем второй признак
Windy
2/3
TRUE
1/1
FALSE
1/2
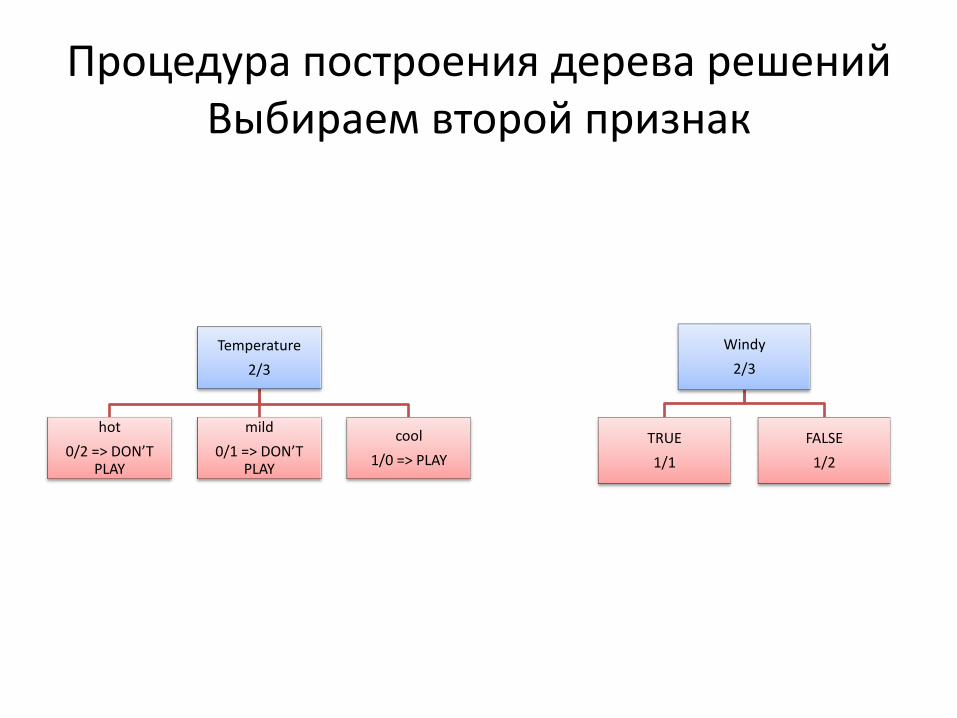
Процедура построения дерева решений Выбираем второй признак
Temperature
2/3
hot
0/2 => DON’T PLAY
mild
0/1 => DON’T PLAY
cool
1/0 => PLAY
Windy
2/3
TRUE
1/1
FALSE
1/2
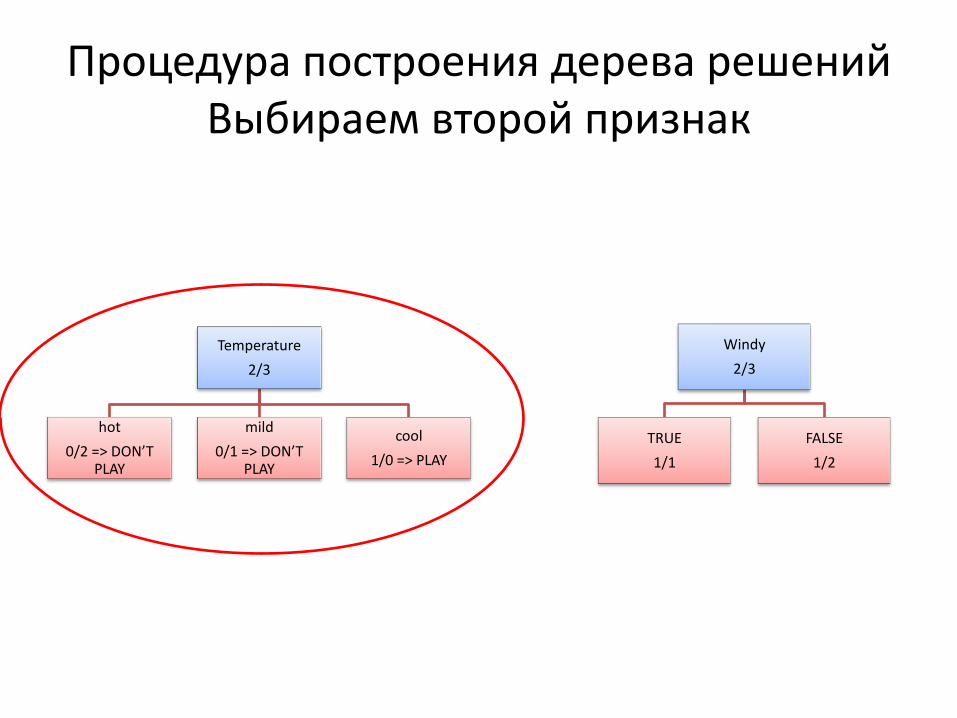
Процедура построения дерева решений Выбираем второй признак
Temperature
2/3
hot
0/2 => DON’T PLAY
mild
0/1 => DON’T PLAY
cool
1/0 => PLAY
Windy
2/3
TRUE
1/1
FALSE
1/2
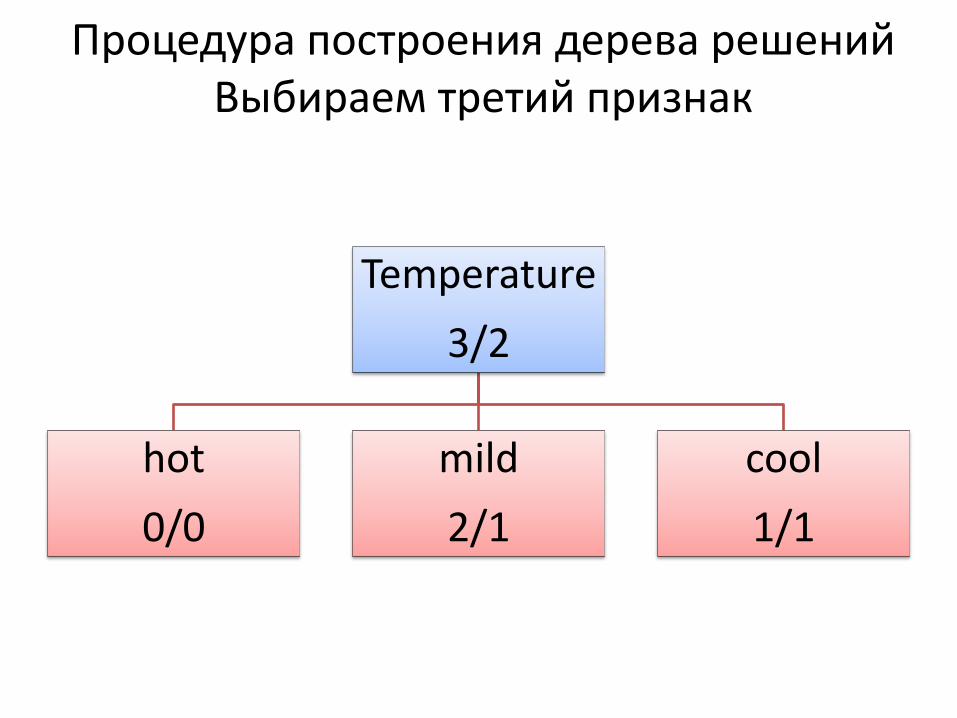
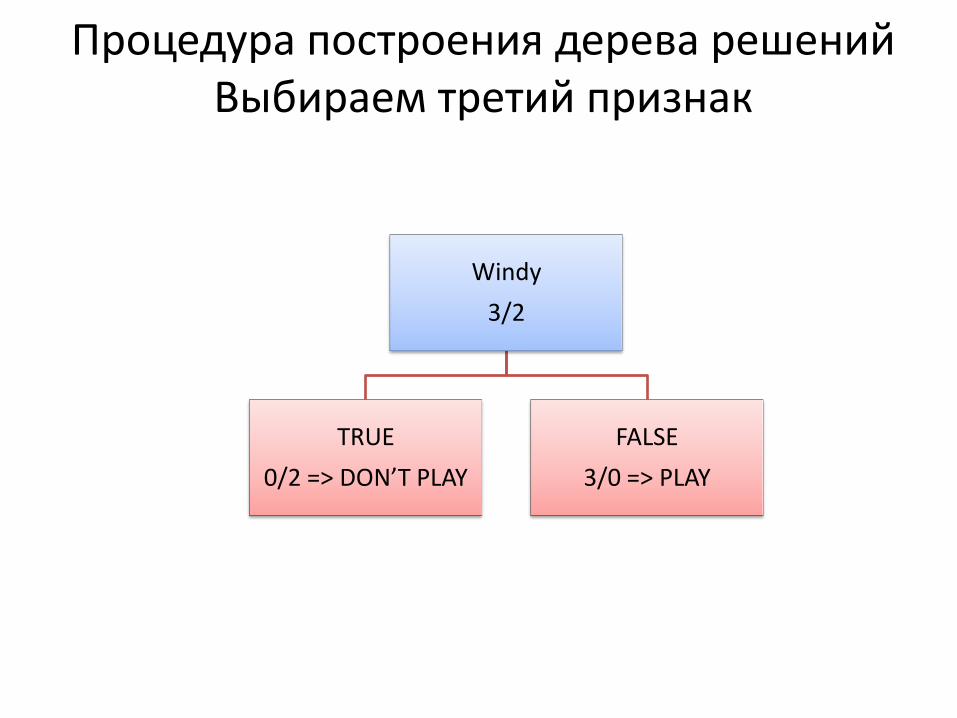
Процедура построения дерева решений Выбираем третий признак
Temperature
3/2
hot
0/0
mild
2/1
cool
1/1
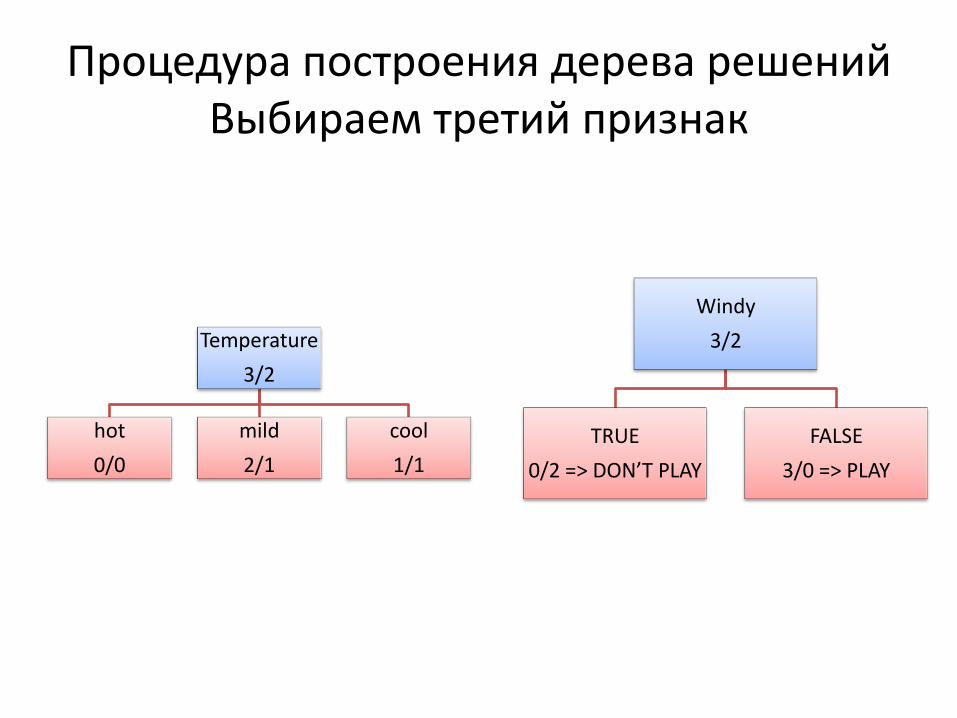
Процедура построения дерева решений Выбираем третий признак
Windy
3/2
TRUE
0/2 => DON’T PLAY
FALSE
3/0 => PLAY
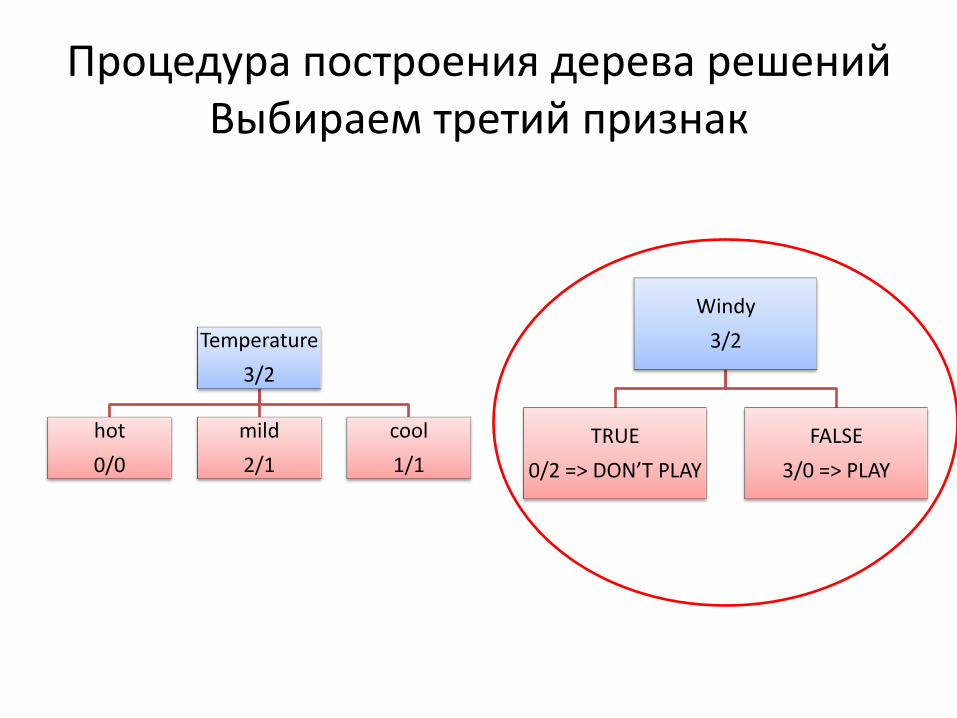
Процедура построения дерева решений Выбираем третий признак
Temperature
3/2
hot
0/0
mild
2/1
cool
1/1
Windy
3/2
TRUE
0/2 => DON’T PLAY
FALSE
3/0 => PLAY
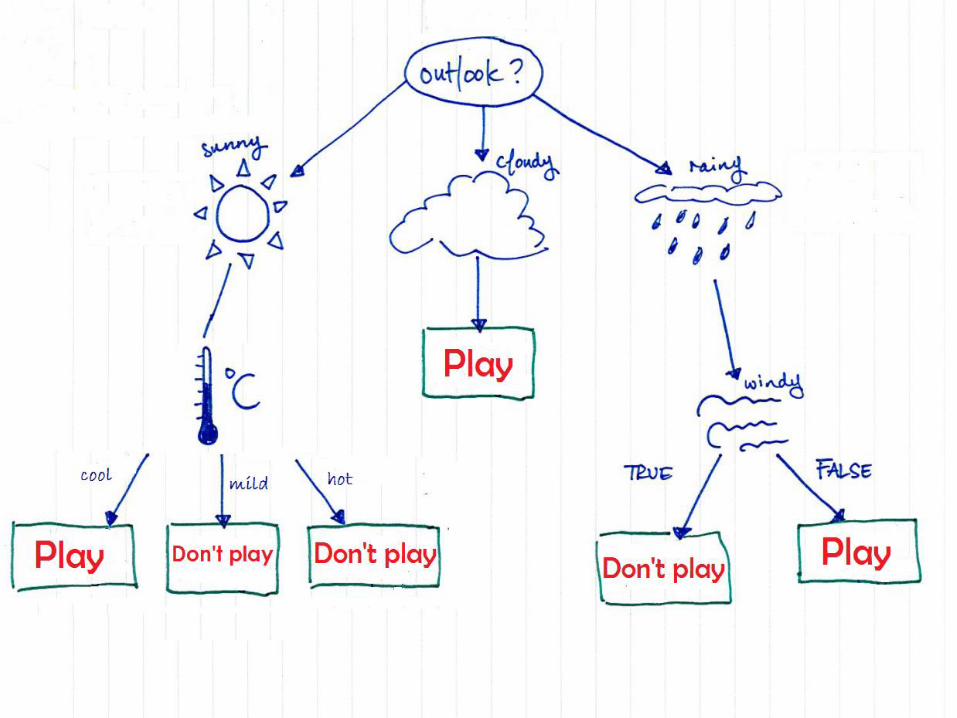
Процедура построения дерева решений Выбираем третий признак
Temperature
3/2
hot
0/0
mild
2/1
cool
1/1
Windy
3/2
TRUE
0/2 => DON’T PLAY
FALSE
3/0 => PLAY

Область применения деревьев решений
• Банковское дело
• Промышленность. Контроль за качеством
продукции, испытания без разрушений
• Медицина
• Молекулярная биология
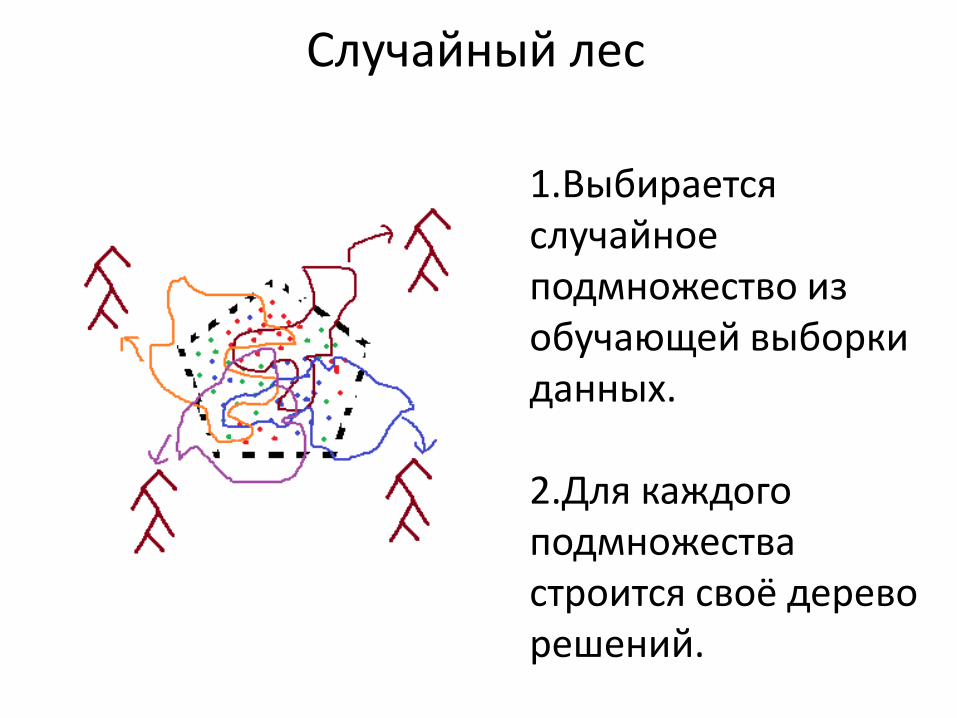
Случайный лес
1.Выбирается случайное подмножество из обучающей выборки данных.
2.Для каждого подмножества строится своё дерево решений.

Практическое применение

Оценка качества классификации
Точность системы – это доля документов, действительно принадлежащих данной категории, относительно всех документов, которые система отнесла к этой категории.
Полнота системы – это доля найденных
классификатором документов, принадлежащих категории, относительно всех документов этой категории в тестовой выборке.

Пример вычисления F-меры
Тестовые данные (10 сообщений):
• 6 спам
• 4 не спам
Что выдал классификатор:
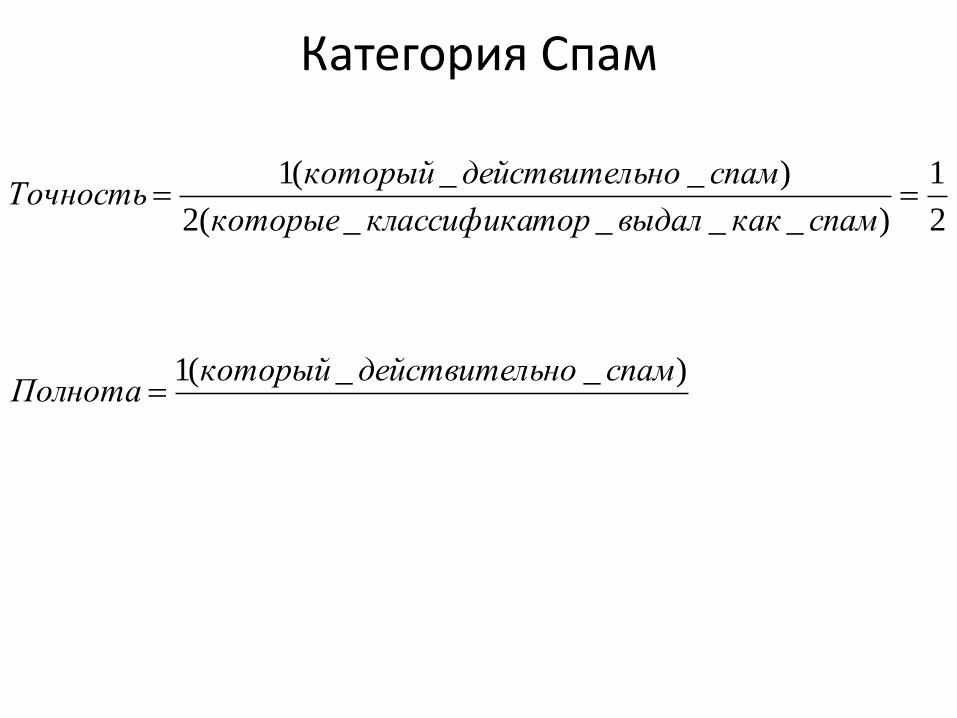
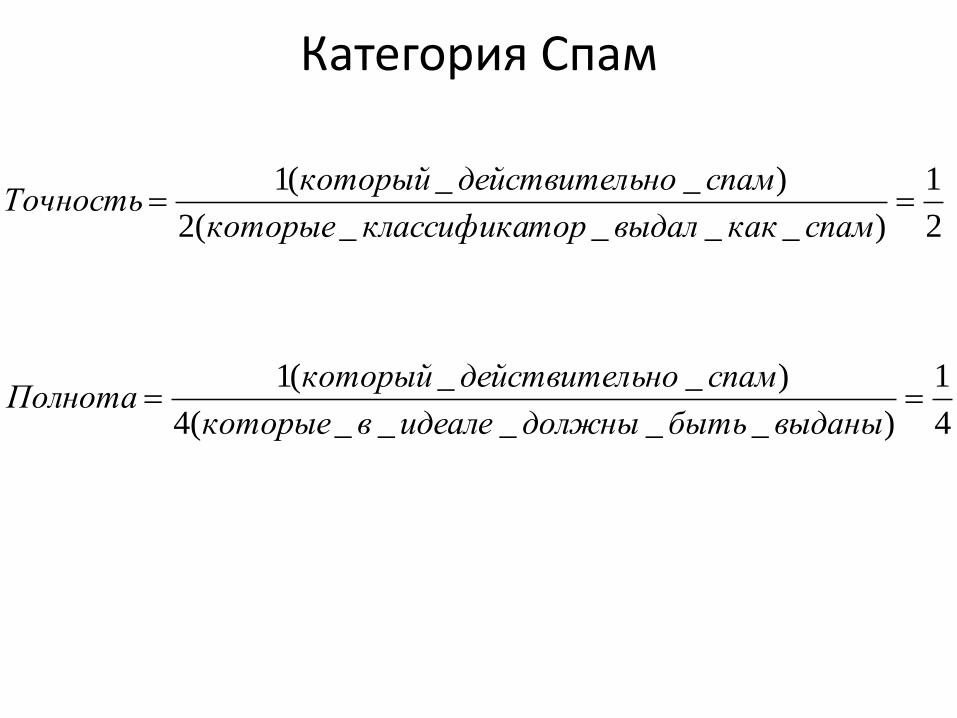
• 2 спам. На самом деле: 1 спам и 1 не спам
• 8 не спам. На самом деле: 3 спам и 5 не спам
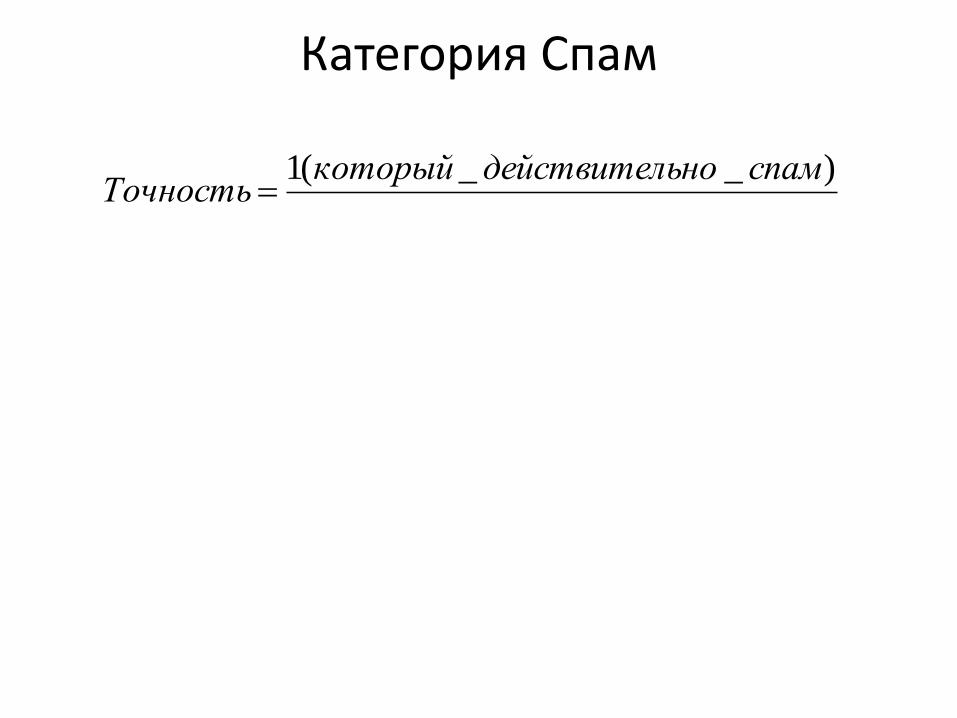
Категория Спам
)__(1 спамьнодействителкоторыйТочность

Категория Спам
2
1
)____(2
)__(1
спамкаквыдалторклассификакоторые
спамьнодействителкоторыйТочность
Категория Спам
)__(1
2
1
)____(2
)__(1
спамьнодействителкоторыйПолнота
спамкаквыдалторклассификакоторые
спамьнодействителкоторыйТочность
Категория Спам
4
1
)_____(4
)__(1
2
1
)____(2
)__(1
выданыбытьдолжныидеалевкоторые
спамьнодействителкоторыйПолнота
спамкаквыдалторклассификакоторые
спамьнодействителкоторыйТочность
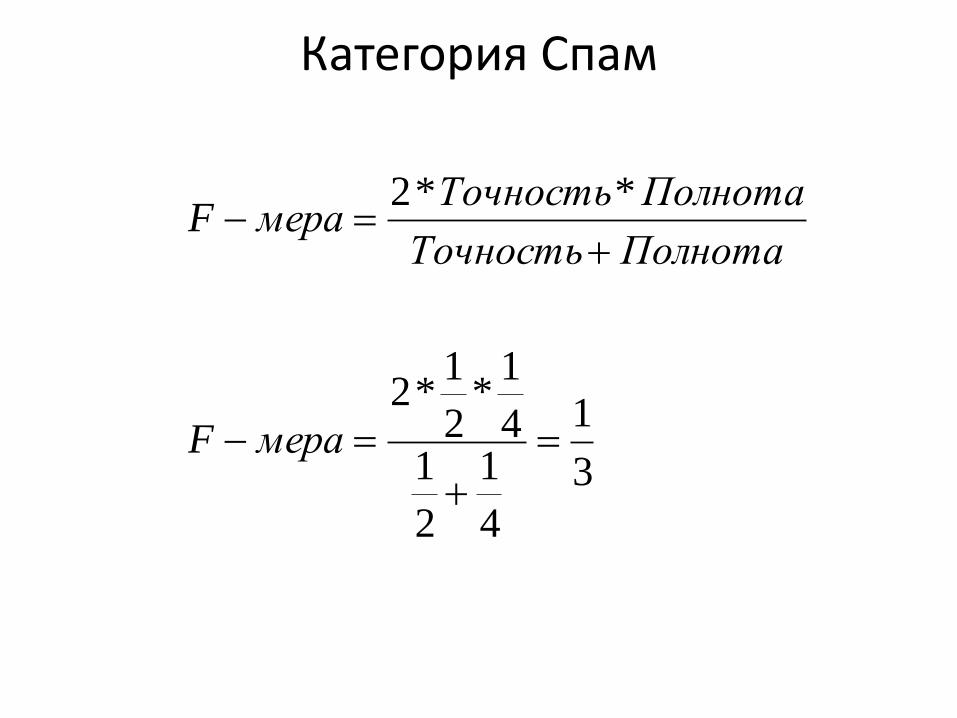
Категория Спам
3
1
4
1
2
14
1*
2
1*2
**2
мераF
ПолнотаТочность
ПолнотаТочностьмераF

Недообучение и переобучение
Обучающая кривая:
• зависимость ошибки модели от объёма на данных, использованных для обучения
• зависимость ошибки от объёма на тестовых данных

Недообучение и переобучение (продолжение)
Модель: • Недообучена – не смогла отобразить
существенные зависимости
• Хорошо обучена
• Переобучена – воспроизводит не только существенные зависимости, но и случайные отклонения, свойственные только обучающим данным
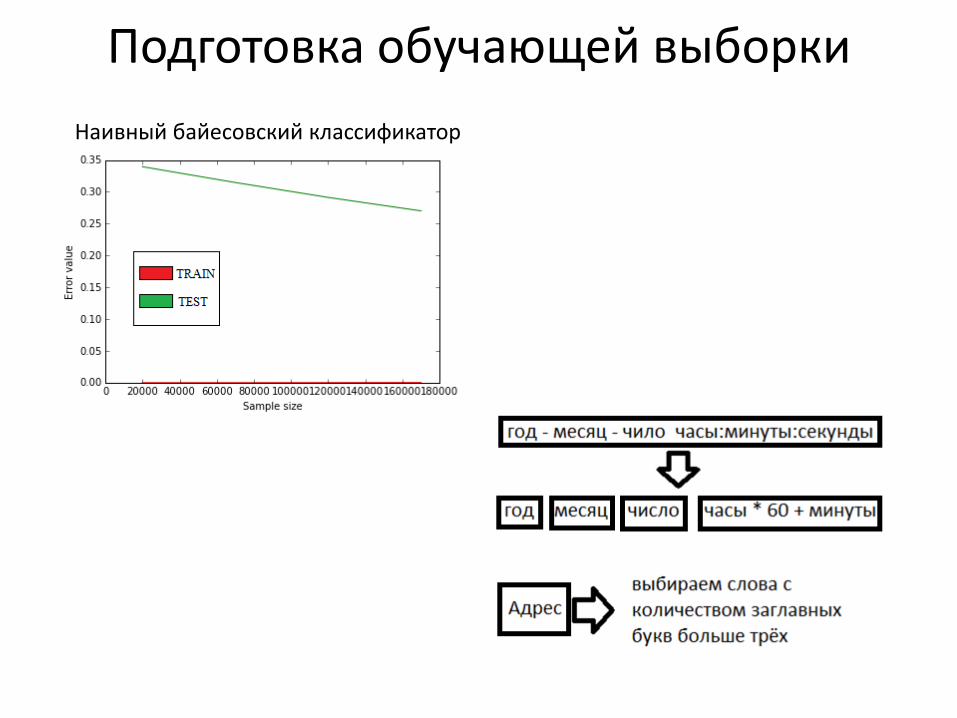
Подготовка обучающей выборки
Наивный байесовский классификатор
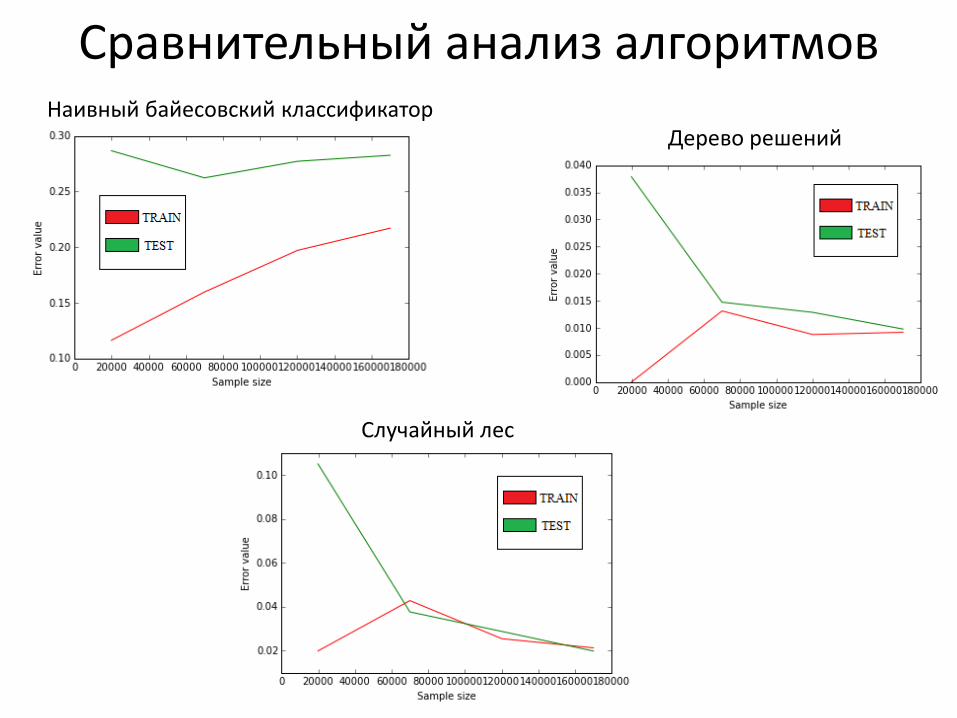
Сравнительный анализ алгоритмов Наивный байесовский классификатор
Случайный лес
Дерево решений
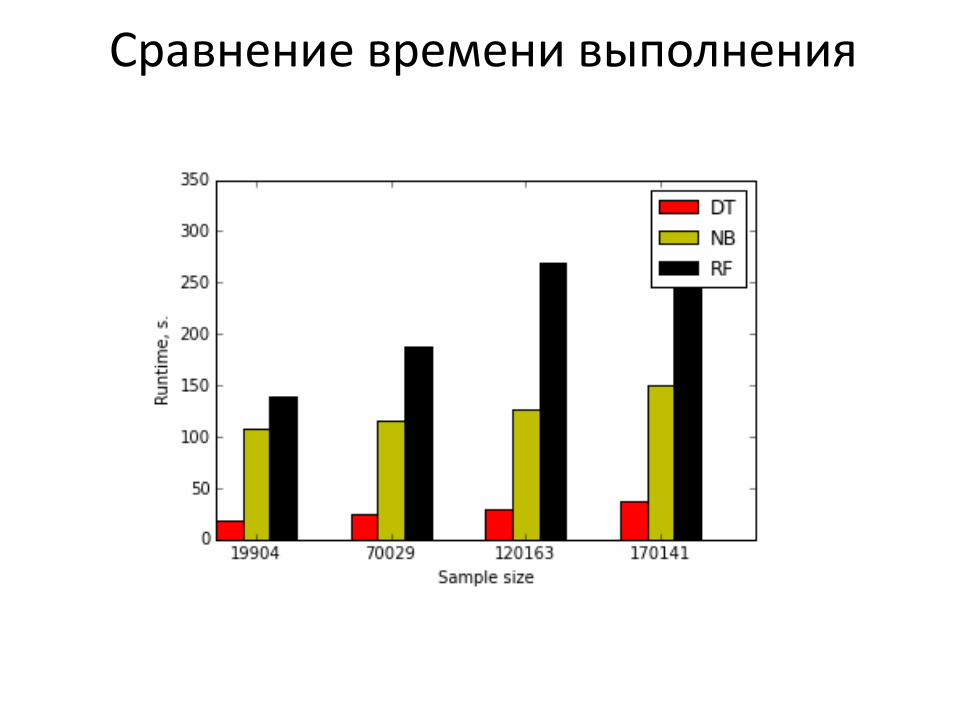
Сравнение времени выполнения

+ Обработка отсутствующих значений + Обучение и классификация сводятся к простым математическим операциям над вероятностями признаков + Обучение проводится инкрементно — Предположение независимости признаков — Решается только задача классификации
Достоинства и недостатки байесовского классификатора

Достоинства и недостатки деревьев решений
+ Интуитивно понятная и легко интерпретируемая классификационная модель + Не требует подготовки данных + Быстрый процесс обучения — Построение оптимального дерева решений — NP-полная задача — Абсолютно не способен к экстраполяции

Достоинства и недостатки случайного леса
+ Не чувствительность к масштабированию значений признаков + Возможность распараллелить + Высокая масштабируемость — Сложная интерпретация модели — Большой размер получающихся моделей — Классификация занимает большее количество времени

Выводы
Рассмотренные алгоритмы являются неплохой альтернативой, в тех случаях когда надоедает подстраивать абстрактные веса и коэффициенты в других алгоритмах классификации либо когда приходится обрабатывать данные со смешанными (категориальными и числовыми) атрибутами.


















