
© 2008 SRI International Question Asking to Inform Preference Learning: A Case Study Melinda...
18
© 2008 SRI International Question Asking to Inform Preference Learning: A Case Study Melinda Gervasio SRI International Karen Myers SRI International Marie desJardins Univ. of Maryland Baltimore County Fusun Yaman BBN Technologies AAAI Spring Symposium: Humans Teaching Agents March 2009
-
Upload
david-stone -
Category
Documents
-
view
215 -
download
0
Transcript of © 2008 SRI International Question Asking to Inform Preference Learning: A Case Study Melinda...

© 2008 SRI International
Question Asking to Inform Preference Learning: A Case Study
Melinda GervasioSRI International
Karen MyersSRI International
Marie desJardinsUniv. of Maryland Baltimore County
Fusun YamanBBN Technologies
AAAI Spring Symposium: Humans Teaching AgentsMarch 2009
AAAI 2009 Spring Symposium: Humans Teaching Agents 2
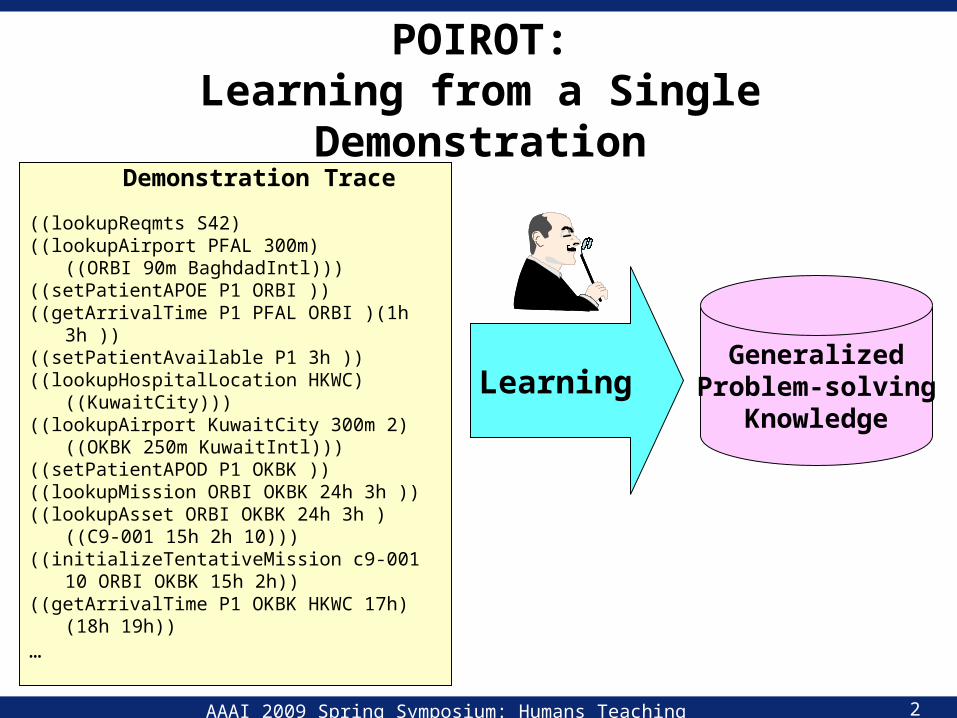
POIROT:Learning from a Single Demonstration
Demonstration Trace
((lookupReqmts S42) ((lookupAirport PFAL 300m)
((ORBI 90m BaghdadIntl)))((setPatientAPOE P1 ORBI ))((getArrivalTime P1 PFAL ORBI )(1h 3h ))((setPatientAvailable P1 3h ))((lookupHospitalLocation HKWC)
((KuwaitCity)))((lookupAirport KuwaitCity 300m 2)
((OKBK 250m KuwaitIntl)))((setPatientAPOD P1 OKBK ))((lookupMission ORBI OKBK 24h 3h ))((lookupAsset ORBI OKBK 24h 3h )
((C9-001 15h 2h 10)))((initializeTentativeMission c9-001 10 ORBI
OKBK 15h 2h))((getArrivalTime P1 OKBK HKWC 17h)
(18h 19h))…
Learning Generalized
Problem-solvingKnowledge
AAAI 2009 Spring Symposium: Humans Teaching Agents 3
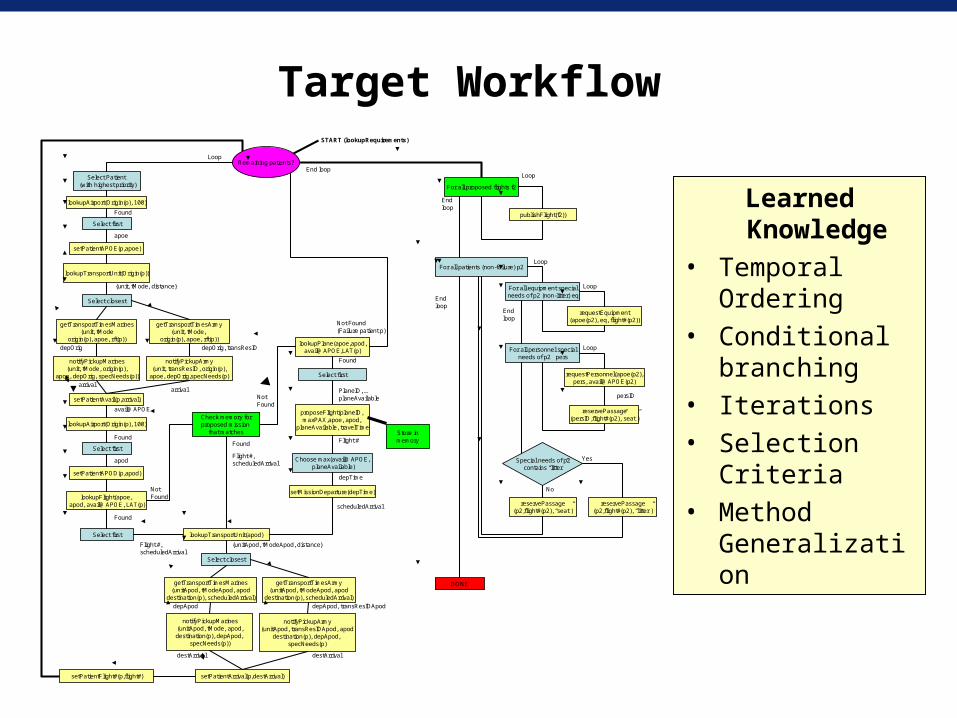
Target Workflow
Learned Knowledge
• Temporal Ordering
• Conditional branching
• Iterations• Selection
Criteria• Method
Generalization
Select Patient (with highest priority)
lookupAirport(Origin(p), 100)
Select first
Select first
lookupPlane(apoe,apod,avail@APOE,LAT(p)
Found
setPatientAPOE(p,apoe)
apoe
getTransportTimesArmy(unit, tMode,
origin(p), apoe, rft(p))
setPatientAvail(p,arrival)
depOrig
lookupAirport(Origin(p), 100)
Select first
Found
setPatientAPOD(p,apod)
apod
lookupFlight(apoe, apod, avail@APOE, LAT(p)
Found
Flight #,scheduledArrival
avail@APOE
Not Found
Not Found(Failure patient p)
Select first
Choose max(avail@APOE,planeAvailable)
setMissionDeparture(depTime)
Found
depTime
PlaneID, …planeAvailable
scheduledArrival
proposeFlight(planeID, maxPAX,apoe, apod,
planeAvailable, travelTime
Flight #
setPatientFlight#(p,flight#)
Remaining patients?
For all proposed flights f2
publishFlight(f2))
For all patients (non-failure) p2
reservePassage(p2,flight#(p2), “seat”)
DONE
Endloop
Endloop
Loop
Loop
START (lookupRequirements)
Not Found
Found
Flight #,scheduledArrival
Check memory forproposed mission
that matches
End loop
Loop
Store inmemory
lookupTransportUnit(Origin(p))
Select closest
getTransportTimesMarines(unit, tMode
origin(p), apoe, rft(p))
{unit, tMode, distance}
depOrig, transResID
notifyPickupMarines(unit, tMode, origin(p),
apoe, depOrig, specNeeds(p))
notifyPickupArmy(unit, transResID, origin(p),
apoe, depOrig,specNeeds(p)arrival
arrival
getTransportTimesArmy(unitApod, tModeApod, apod
destination(p), scheduledArrival)depApod
lookupTransportUnit(apod)
Select closest
getTransportTimesMarines(unitApod, tModeApod, apod
destination(p), scheduledArrival)
{unitApod, tModeApod, distance}
notifyPickupMarines(unitApod, tMode, apod,destination(p), depApod,
specNeeds(p))
notifyPickupArmy(unitApod, transResIDApod, apod
destination(p), depApod, specNeeds(p)
destArrival destArrival
depApod, transResIDApod
setPatientArrival(p,destArrival)
requestPersonnel(apoe(p2),pers, avail@APOE(p2)
requestEquipment(apoe(p2), eq, flight#(p2))
For all equipment specialneeds of p2 (non-litter) eq
Endloop
For all personnel specialneeds of p2 pers
Loop
Loop
reservePassage(persID,flight#(p2),”seat”)
persID
Special needs of p2contains “litter”
reservePassage(p2,flight#(p2), “litter”)
No
Yes

AAAI 2009 Spring Symposium: Humans Teaching Agents 4
QUAIL:Question Asking to Inform Learning
Goal: improve learning performance through system-initiated question asking
Approach:1. define question catalog to inform learning by demo2. develop question models and representations3. explore question asking strategies
“Tell me and I forget, show me and I remember, involve me and I understand.”
- Chinese Proverb

AAAI 2009 Spring Symposium: Humans Teaching Agents 5
Question Models
Question Cost: approximate ‘cognitive burden’ in answering
Cost(q) = wF ×FormatCost(q) + wG×GroundednessCost(q)
wF + wG = 1
Question Utility: normalize utilities across learners
Utility(q) = ∑lL wl × Utilityl(q,l) where ∑ wl = 1
Utilityl(q) = wB × BaseUtilityl(q) + wG × GoalUtilityl(q)
wB + wG = 1

AAAI 2009 Spring Symposium: Humans Teaching Agents 6
Question Selection
• Given:
– questions Q={q1 … qn} with costs and utilities
– budget B
• Problem: find Q'⊆Q with Cost(Q') ≤ B with maximal utility– equivalent to 0/1 knapsack problem (no
question dependencies)– efficient dynamic programming approaches –
O(nB)
AAAI 2009 Spring Symposium: Humans Teaching Agents 7
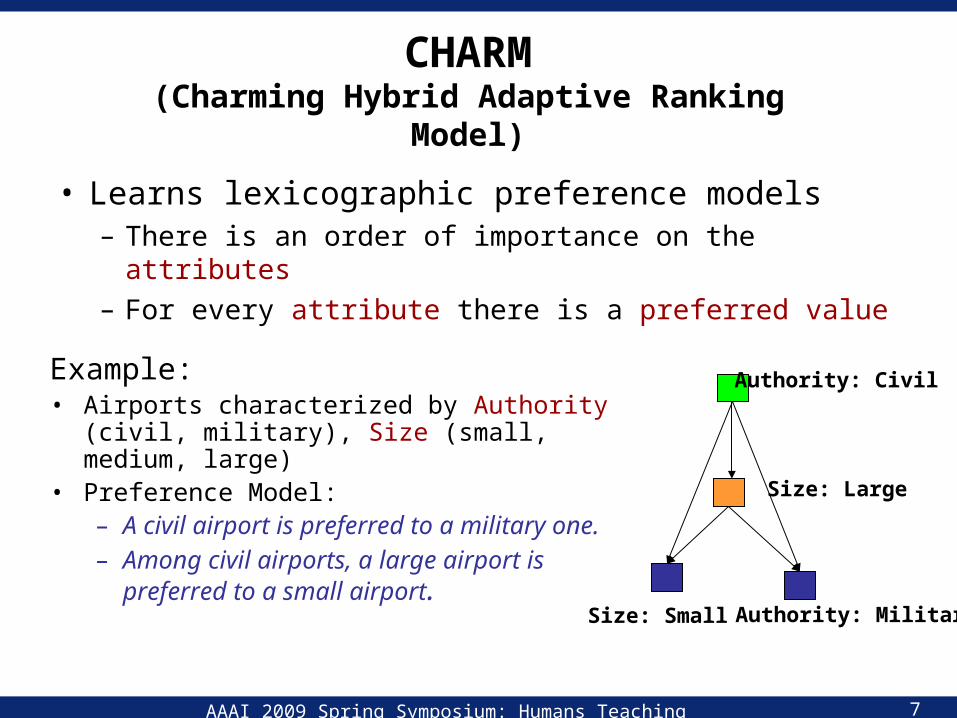
CHARM(Charming Hybrid Adaptive Ranking Model)
• Learns lexicographic preference models– There is an order of importance on the attributes– For every attribute there is a preferred value
Size: Small
Authority: Civil
Size: Large
Authority: Military
Example:• Airports characterized by Authority (civil,
military), Size (small, medium, large)• Preference Model:
– A civil airport is preferred to a military one.– Among civil airports, a large airport is
preferred to a small airport.

AAAI 2009 Spring Symposium: Humans Teaching Agents 8
CHARM Learning
• Idea: – Keep track of a set of models consistent with data of the form
Obj1<Obj2 • A partial order on the attributes and values
– The object that is preferred by more models is more preferred
• Algorithm for learning the models– Initially assume all attributes and all values are equally important– Loop until nothing changes
• Given Obj1<Obj2 predict a winner using the current model• If the predicted winner is actually the preferred one then do nothing• Otherwise decrease the importance of the attribute/values that led
to the wrong prediction.

AAAI 2009 Spring Symposium: Humans Teaching Agents 9
Learn From Mistakes
Airport Size Authority
BWI Large Civil
DCA Small Civil
Rank Value
1 Small
1 Large
1 Civil
1 Military
Rank Value
2 Small
1 Large
1 Civil
1 Military
1) Given training data(e.g., BWI<DCA)
2) Most important attributes
predict a winner
3) Ranks of attributes who voted for the looser updated.

AAAI 2009 Spring Symposium: Humans Teaching Agents 10
Learn from Mistakes
Airport Size Authority
BWI Large Civil
Andrews Large Military
Rank Value
2 Small
1 Large
1 Civil
1 Military
Rank Value
2 Small
1 Large
1 Civil
2 Military
Given: BWI<Andrews

AAAI 2009 Spring Symposium: Humans Teaching Agents 11
Finally• If the model truly is lexicographic then ranks will
converge– No convergence => underlying model is not lexicographic.
• If training data is consist then will correctly predict all examples
Size: Small
Authority: Civil
Size: Large
Authority: Military
Rank Value
3 Small
2 Large
1 Civil
3 Military

AAAI 2009 Spring Symposium: Humans Teaching Agents 12
QUAIL+CHARM Case Study
Goal: investigate how different question selection strategies impact CHARM preference learning for ordering patients
Performance Metric: CHARM's accuracy in predicting pairwise ordering preferences
Learning Target: lexicographic preference model for ordering patients defined over a subset of 5 patient attributes• triageCode, woundType, personClass, readyForTransport, LAT
Training Input: P1<P2 indicating P1 is at least as preferred as P2

AAAI 2009 Spring Symposium: Humans Teaching Agents 13
Question Types for CHARM
• Object ordering: Should Patient1 be handled before Patient2?• Attribute relevance: Is Attr relevant to the ordering?• Attribute ordering: Is Attr1 preferred to Attr2?• Attribute value ordering: For Attr, is Val1 preferred to Val2?
Uniform question cost model

AAAI 2009 Spring Symposium: Humans Teaching Agents 14
Experiment Setup
• Target preference models generated randomly– Draw on database of 186 patient records
• Train on 1 problem; test on 4 problems – Training/test instance: a pairwise preference among 5 patients
• 10 runs for each target preference model– 3 handcrafted target models with irrelevant attributes– 5 randomly generated target models over all 5 patient attributes
AAAI 2009 Spring Symposium: Humans Teaching Agents 15
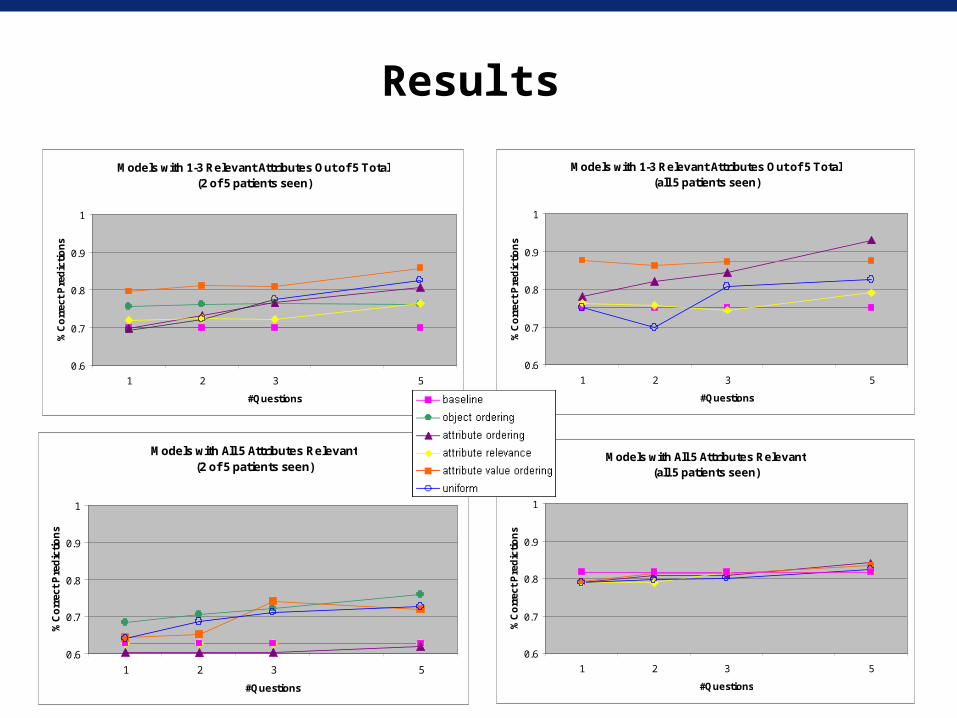
Models with All 5 Attributes Relevant(2 of 5 patients seen)
0.6
0.7
0.8
0.9
1
1 2 3 5
#Questions
%C
orr
ect
Pre
dic
tio
ns
Results
Models with 1-3 Relevant Attributes Out of 5 Total(2 of 5 patients seen)
0.6
0.7
0.8
0.9
1
1 2 3 5
#Questions
%C
orr
ect
Pre
dic
tio
ns
Models with 1-3 Relevant Attributes Out of 5 Total(all 5 patients seen)
0.6
0.7
0.8
0.9
1
1 2 3 5
#Questions
%C
orr
ect
Pre
dic
tio
ns
Models with All 5 Attributes Relevant(all 5 patients seen)
0.6
0.7
0.8
0.9
1
1 2 3 5
#Questions
%C
orr
ect
Pre
dic
tio
ns

AAAI 2009 Spring Symposium: Humans Teaching Agents 16
Observations on Results
Question answering is generally useful• Increased number of questions (generally) results in greater
performance improvements• Has greater impact when fewer training examples available for
learning (i.e., learned model is weaker)
A little knowledge can be a dangerous thing – CHARM’s incorporation of isolated answers can decrease
performance– Related questions can lead to significant performance improvement
• Being told {Attr1>Attr2, Attr4>Attr5} may not be useful (and may be harmful)
• Being told {Attr1>Attr2, Attr2>Attr3} is very useful
Need for more sophisticated models of question utility• Learn the utility models

AAAI 2009 Spring Symposium: Humans Teaching Agents 17
Future Directions
• Learn utility models through controlled experimentation– Assess the impact of different question types in different settings– Features for learning:
• Question attributes, state of learned model, training data, previously asked questions
• Expand set of questions, support questions with differing costs
• Expand coverage to a broader set of Learners
• Continuous model of question asking

AAAI 2009 Spring Symposium: Humans Teaching Agents 18
Related Work
• Active Learning:– Focus to date on classification, emphasizing selection
of additional training data for a human to label
• Interactive Task Learning:– Allen et al.’s work on Learning by Discussion– Blythe’s work on Learning by Being Told


















